27/10/2024
Change Bookstack url and context
I love Bookstack, actually I think it’s one of the best wiki project existing.
It’s well documented, it works like charm, the developer is very active (and he’s also a very kind person, which has nothing to do with the software, but it’s always a pleasure interact with him) and it has very nice features:
- a nice and responsive design
- drafts autosave
- MFA out of the box
- diagrams.net integration
It also works perfectly fine in a docker container, technically the official project do not offer a container image, but there are two groups building them and they’re referred directly in the official documentation.
Recently I started to sort things out on my beloved Raspberry PI 5, in particular I’m moving services so I can reverse proxy them on a single Apache httpd instance (you know I still love Apache :D ), today I moved around Bookstack, in particulare I did two things:
- change Bookstack hostname (for example from https://site.domain.tld to https://newsite.domain.tld )
- make Bookstack work under a specific url context (for example https://site.domain.tld/bookstack instead of https://site.domain.tld ).
On my environment I’m using the LinuxServer.io docker image, so check the project site for details, and also I’m using docker compose, if you’re not familiar with it start using it for Reorx’s sake.
Backup
First of all take a damn backup, it’s mandatory.
Seriously I’m not joking.
Stop the containers
cd /data/docker/bookstack ; docker compose down
Backup files with a simple tar, restic, kopia, whatever you want, but DO IT!
cd /data/docker/ ; tar -cpzf /backup/bookstack-backup.tar.gz bookstack
Change Bookstack hostname
This process is documented on the Bookstack documentation (LINK), but still I decided to mention it because the procedure is a little bit different on a docker container, so it’s worth spent a few words about it.
First of all you have to change the APP_URL configuration variable, in case of a docker container it’s enough to change the environment variable on the docker-compose.yaml file, so open the file and change the variable to the new url
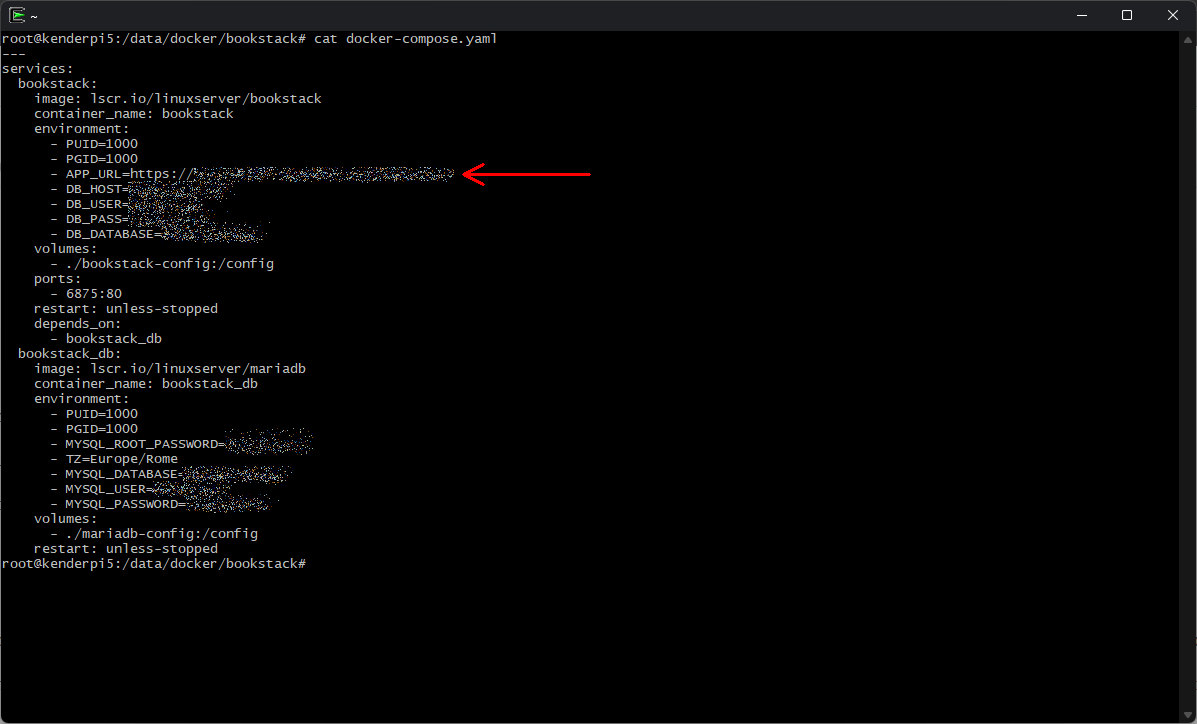
Now you must replace the old url from the database record with the new one using the bookstack:update-url command, in case of a docker container you must identify where’s the Laravel framework artisan file and launch it accordingly to the documentation.
docker exec -it bookstack php /app/www/artisan bookstack:update-url https://site.domain.tld https://newsite.domain.tld
After that clear the cache using
docker exec -it bookstack php /app/www/artisan cache:clear
Restart the docker container to change the environment variable you previously changed with the new url.
cd /data/docker/bookstack ; docker compose down ; docker compose up -d
Done, now your Bookstack instance should be reachable to the new url.
Change Bookstack root context
This change is a little bit tricky, because it involves some webserver changes.
First of all you must repeat the same process used for changing the url hostname of your Bookstack instance, this time including the context you want to use (for example /bookstack ).
Let’s quickly review the steps:
1) Change the APP_URL environment variable in the docker-compose.yaml (APP_URL=https://newsite.domain.tld/bookstack in this case)
2) Replace the url in the database using the bookstack:update-url
docker exec -it bookstack php /app/www/artisan bookstack:update-url https://newsite.domain.tld https://newsite.domain.tld/bookstack
3) Clear Bookstack cache
docker exec -it bookstack php /app/www/artisan cache:clear
4) Restart the docker container to change the environment variable you previously changed with the new url.
cd /data/docker/bookstack ; docker compose down ; docker compose up -d
Now you must review the webserver configuration inside your docker container, in case of the LinuxServer.io container there’s a nginx instance running inside the container, you can fine its configuration inside the /config/nginx/ directory inside the container.
If you followed the LinuxServer.io recommendations the /config directory should be a persistent volume (or a persistent path on your docker host), so any changes in the nginx configuration files should not be lost in case of a container restart.
In my case the config persistent volume is located in the /data/docker/bookstack/bookstack-config directory, so the nginx configuration is located in the file /data/docker/bookstack/bookstack-config/nginx/site-confs/default.conf.
Apply this patch
wget https://tasslehoff.burrfoot.it/pub/bookstack-nginx.patch ; \ patch /data/docker/bookstack/bookstack-config/nginx/site-confs/default.conf < bookstack-nginx.patch
Reload nginx configuration
docker exec -it bookstack nginx -s reload
Done, now your Bookstack instance should work at the new url https://newsite.domain.tld/bookstack