10/11/2015
Nagios check_oracle_health
Here we are with a new monitoring post, and remember, every day spent working on Nagios is always a great day! :)
This time I want to talk about an awsome Nagios plugin made by ConSol Labs named check_oracle_health.
As you can imagine this extension works on Oracle database and it’s really incredibly helpful for every sysadmin who works with this product, It’s super easy to implement, It’s super easy to understand and It’s super light and efficient compared to the monstrous official Oracle Enterprise Manager.
Assuming you already have a fully functional Nagios server (it’s not important which versions, I tried this plugin on version 2.9 until the latest) you can choose to install check_oracle_health on the Oracle server itself or on another server who has Oracle client with sqlplus installed (to be honest I haven’t tried this second scenario, but I think can work in the same way).
The plugin can work with perl DBD::Oracle or sqlplus client, in this tutorial I will use sqlplus.
First of all download the plugin tar.gz archive, decompress it and enter in its directory
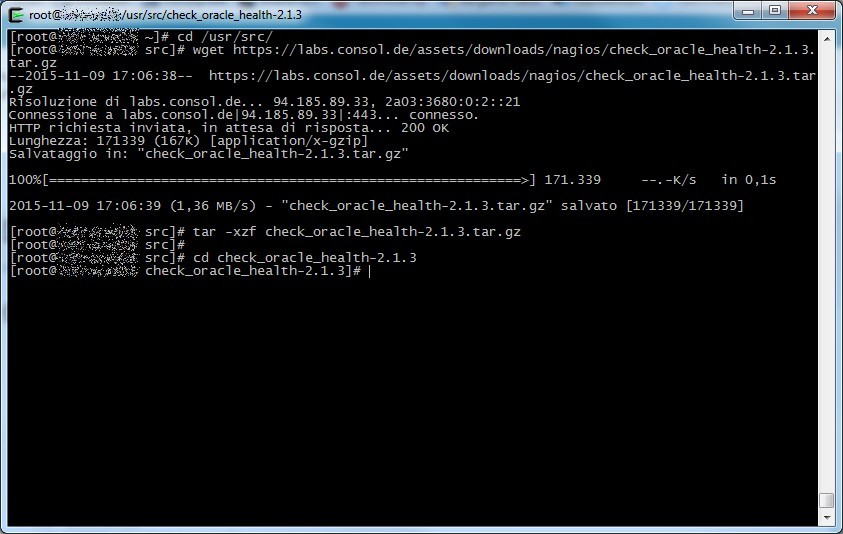
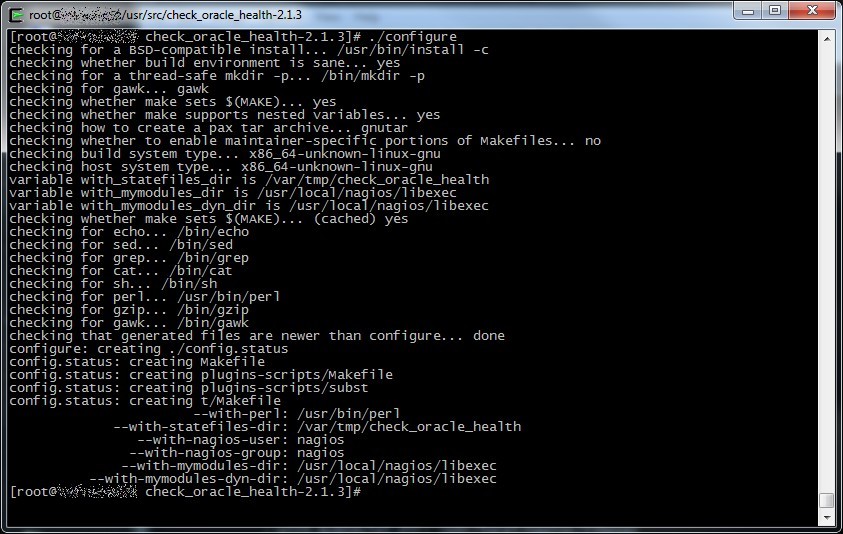
After that procede with the classic configure+make+make install procedure like any other GNU/Linux software source, if you want you can change some options, try “./configure –help” for more informations.
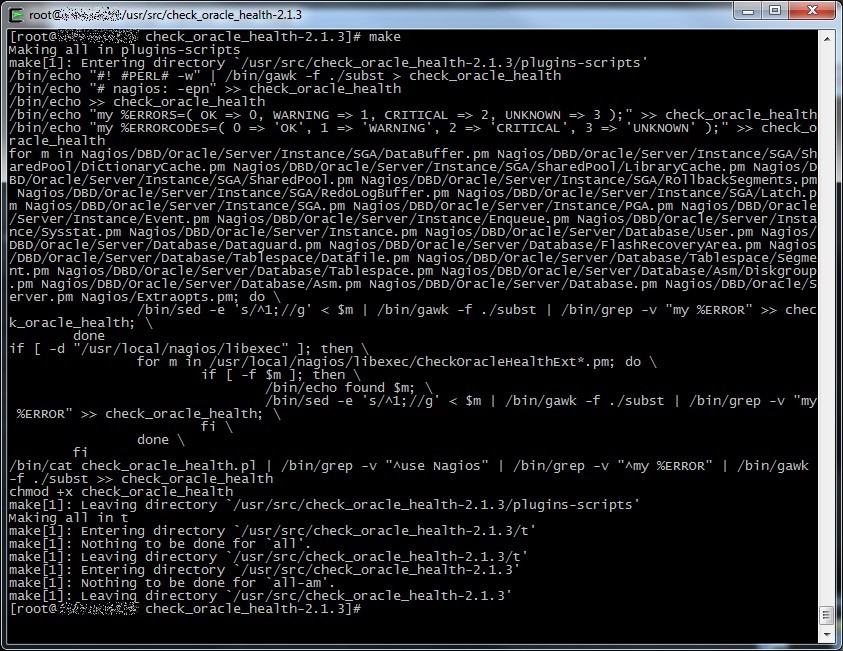
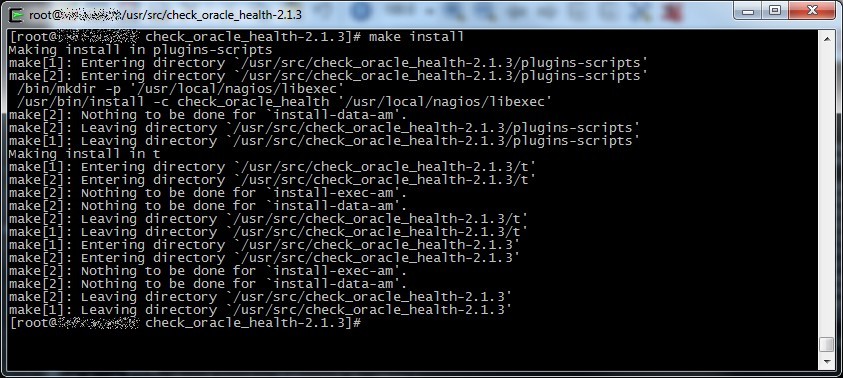
Ok, now we have our plugin ready to work, try to launch /usr/local/nagios/libexec/check_oracle_health to verify it’s ok (check the path if you changed it during the configure phase).
Now the nasty part, as I said I will use sqlplus, which require you’ll set the right environment variables to work (NLS_LANG, ORACLE_HOME, ORACLE_BASE, PATH); you can find them logging the database user (for example oracle) and check the user profile (for example inside the ~/.bash_profile).
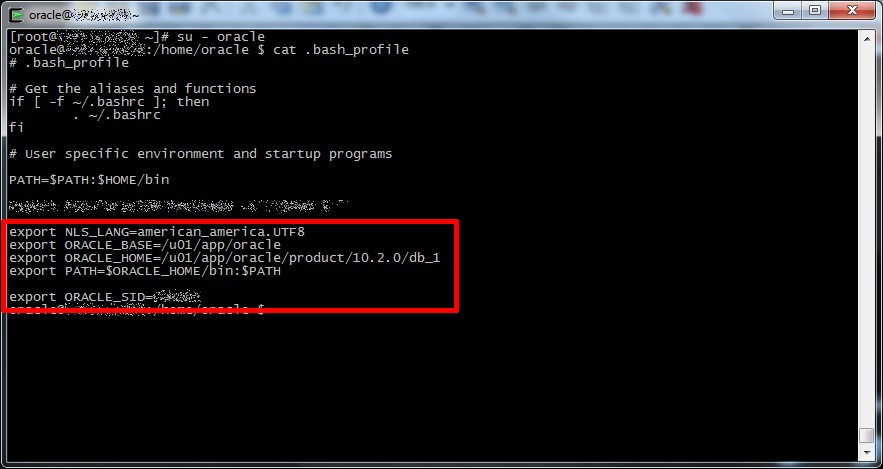
In our scenario we will use nrpe to remotely run our Nagios services, so we have to export this variables for nrpe daemon, to do this you can insert these variables inside the init script for the nrpe daemon (/etc/init.d/nrpe) or inside any incuded file (for example /etc/sysconfig/nrpe) or inside the unit file if you use systemd.
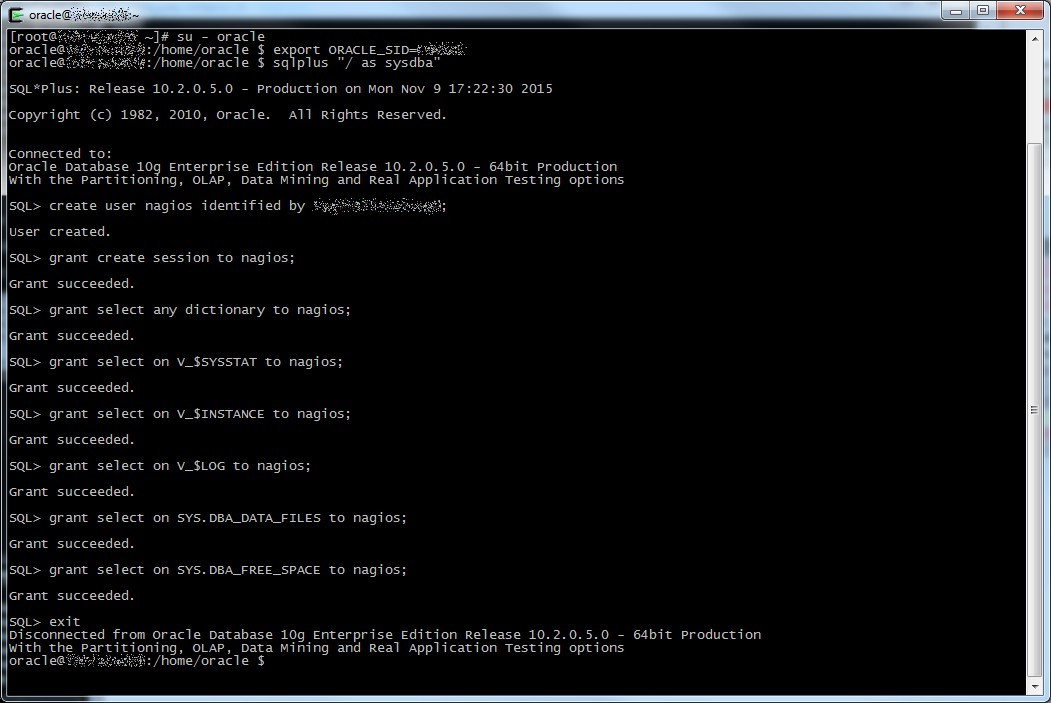
Now on the Oracle database we have to create a user for the plugin and give it the right grants, you don’t want it to use sys or system, don’t you?
Export your ORACLE_SID variable with the right SID, log into sqlplus and launch these commands (change [PASSWORD] with your supersecure password):
create user nagios identified by [PASSWORD]; grant create session to nagios; grant select any dictionary to nagios; grant select on V_$SYSSTAT to nagios; grant select on V_$INSTANCE to nagios; grant select on V_$LOG to nagios; grant select on SYS.DBA_DATA_FILES to nagios; grant select on SYS.DBA_FREE_SPACE to nagios;
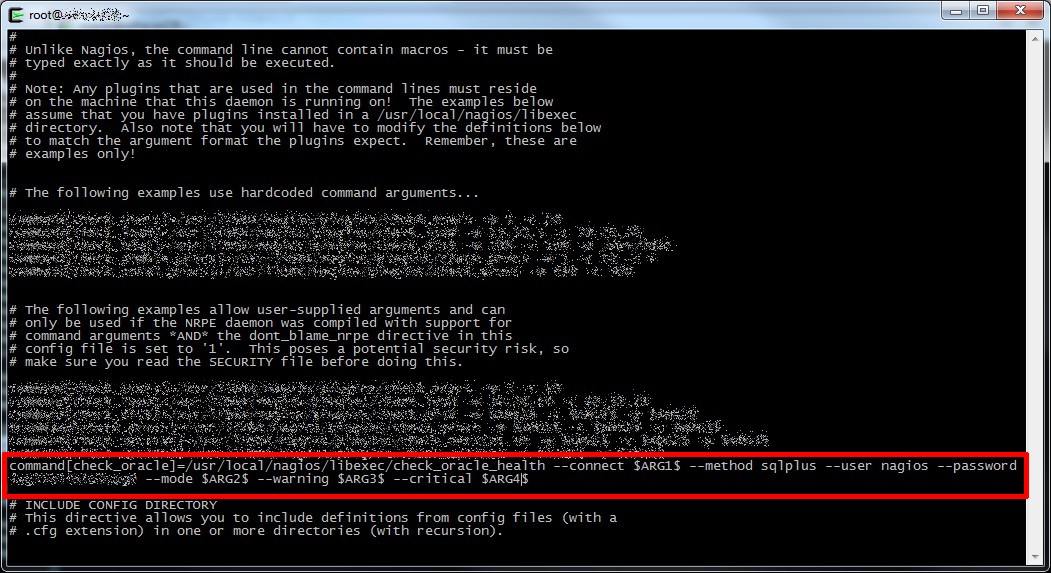
Now let’s change the /etc/nagios/nrpe.conf file, the objective is to create a single nrpe command that will be useful for every service we will define inside Nagios configuration.
To archive this you can use this syntax, it uses command arguments so you need dont_blame_nrpe=1 directive inside the nrpg.conf file or arguments will not work.
command[check_oracle]=/usr/local/nagios/libexec/check_oracle_health --connect $ARG1$ --method sqlplus --user nagios --password [PASSWORD] --mode $ARG2$ --warning $ARG3$ --critical $ARG4$
The arguments are quite simple:
- ARG1 is the SID of the database we want to monitor (check your tnsnames.ora file)
- ARG2 is the specific check we will do with check_oracle_health (read the official documentation for a full list of modes)
- ARG3 is the warning threshold (%)
- ARG4 is the critical threshold (%)
Restart nrpe daemon to activate all the changes
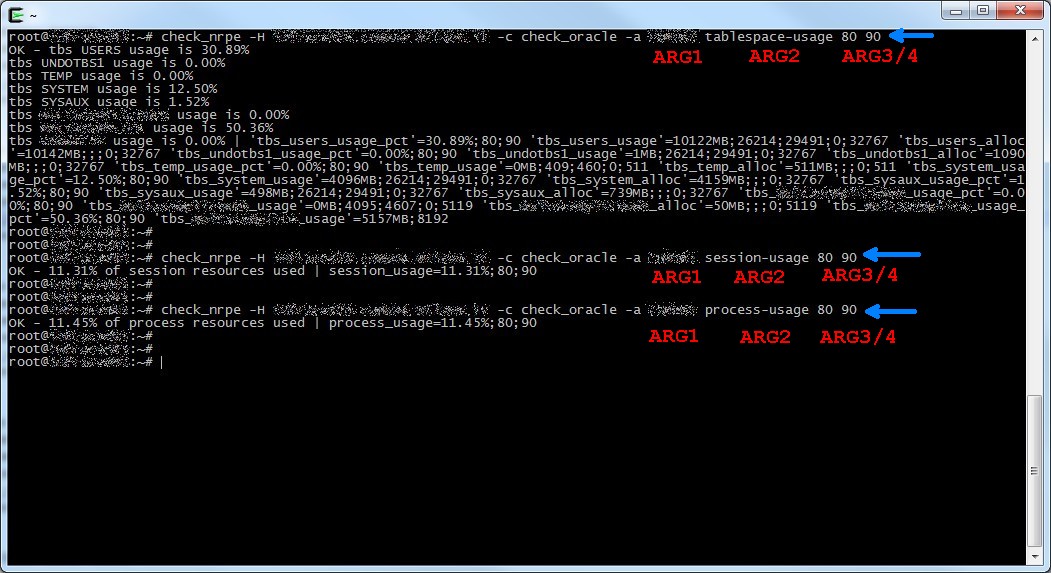
Now let’s try if everythin works, on the Nagios server launch the check_nrpe plugin to simulate what Nagios daemon will do.
This is the syntax:
check_nrpe -H [host or ip address of nrpe server] -c [nrpe command] -a [list of arguments separated by space]
Remember arguments we defined inside the nrpe.conf file:
- ARG1 is the SID, for example MYORADB
- ARG2 is the specific check we will do, for example tablespace-usage
- ARG3 is the warning threshold, for example 80%
- ARG4 is the critical threshold, for example 90%
The last thing you have to do is to finally configure the nrpe service inside Nagios, here is an example of the syntax:
define service{
use generic-service
host_name uberoracle.domain.local
service_description ORACLE tablespaces use
check_command check_nrpe!check_oracle!MYORADB tablespace-usage 80 90
}
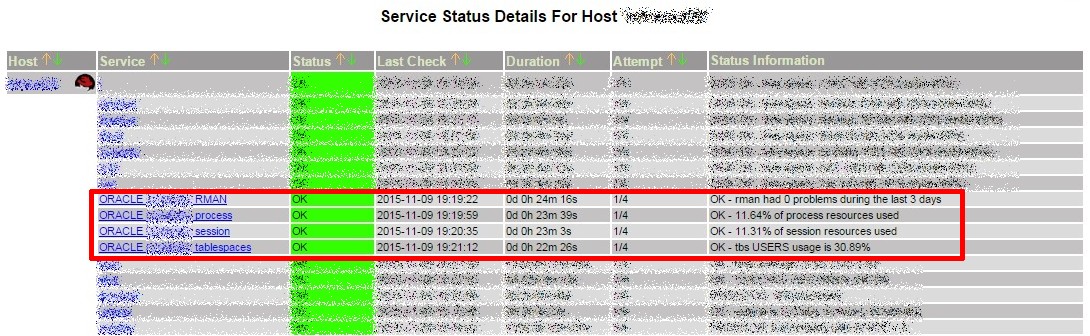
Our shiny new Oracle monitor! (on an ugly old Nagios 2.9…)