

28/09/2013
Rilevazione carico I/O
Dalla mia esperienza professionale ho notato che nella valutazione delle risorse per un server l’aspetto in assoluto più sottovalutato è lo storage.
Molte persone tendono a valutare il carico applicativo solo in termini computazionali e di occupazione ram, lo storage è sempre e solo considerato in termini quantitativi, al massimo vengono valutate misure per garantire continuità di servizio in caso di guasti (es array raid).
Eppure l’esperienza insegna che generalmente le cpu sono sovradimensionate (sono relativamente pochi gli ambiti in cui vengono spremute a dovere), idem per la ram (con la scusa che “costa poco” si tende sempre ad esagerare con questa risorsa), l’unica risorsa che ha mantenuto dei costi piuttosto elevati è lo storage, e guardacaso è proprio la risorsa su cui si tende a risparmiare.
C’è da dire che alla base di questa tendenza c’è anche una buona dose di ignoranza da parte di molti (presunti) specialisti che non sanno rilevare carico di I/O nemmeno quando ce l’hanno davanti al naso, anzi magari lo confondono con carico computazionale consigliando migrazioni a cpu ancora più potenti e quindi “più inutili”.
Rilevare carico di tipo IOWait non è difficile (quantomeno su sistemi operativi unix like), basta il semplice comando “top”…
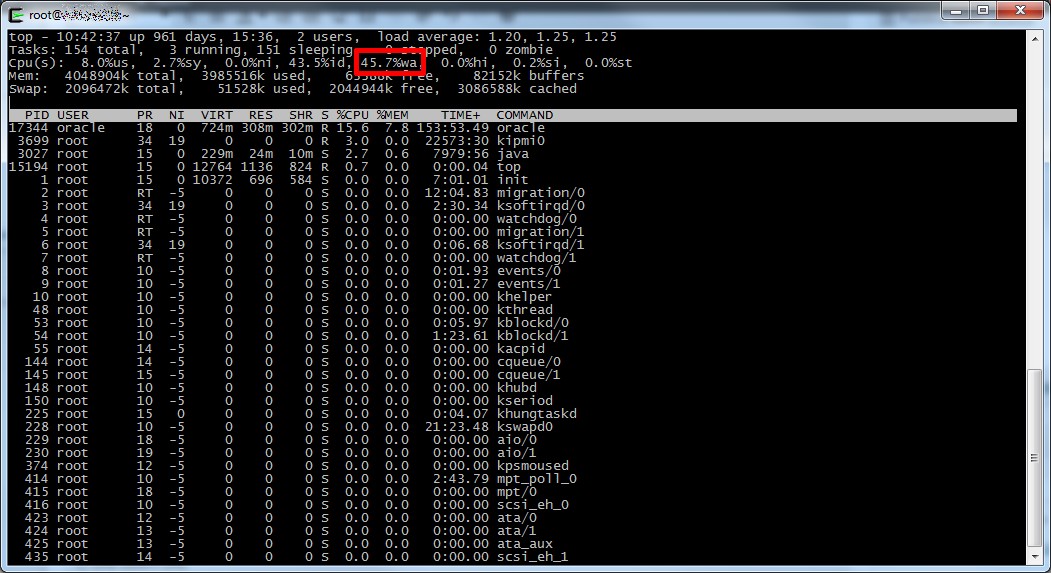
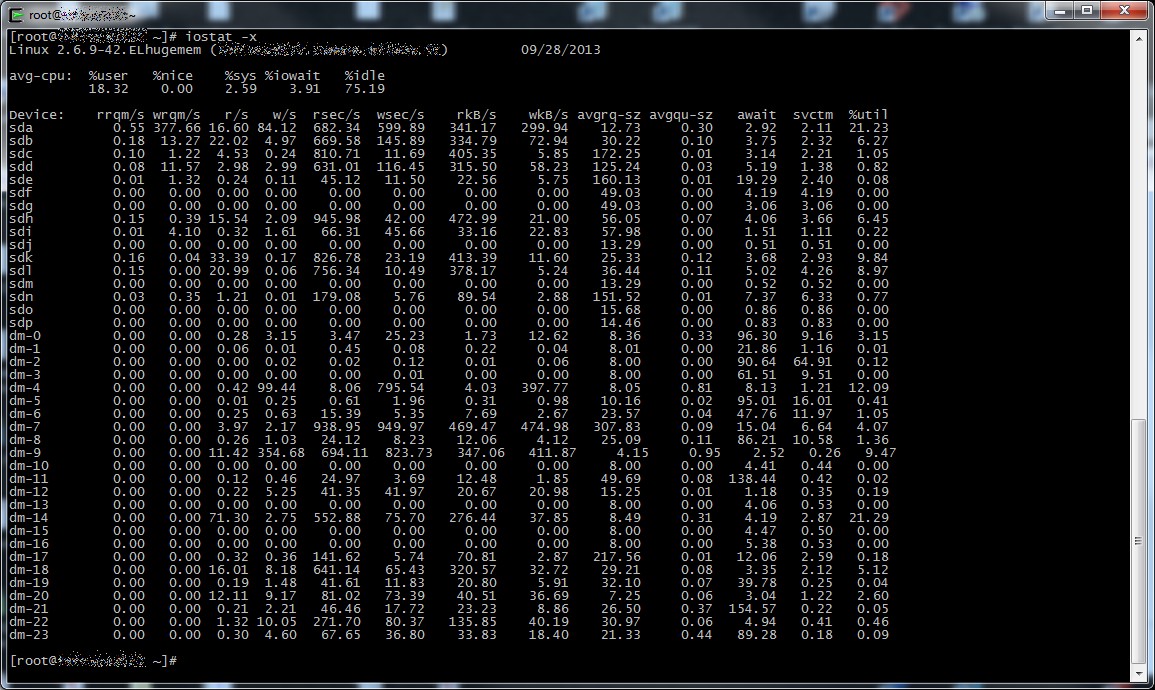
…oppure i fantastici tool del package sysstat
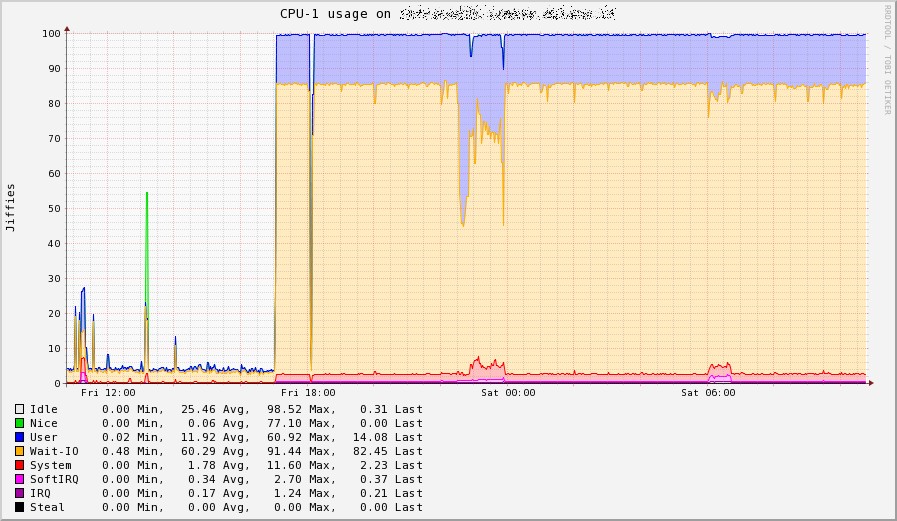
…oppure software un po’ più complessi come Collectd (insieme al fantastico collectd graph panel).
Quello che risulta un po’ più ostico è risalire ai processi responsabili di questo carico, specialmente su macchine un po’ datate.
Sui server con sistemi operativi recenti (ad esempio da Rhel/CentOS 5.x in poi) questo compito è spaventosamente semplificato da uno dei tool che non deve mancare su nessun server, IOtop.

Su macchine più datate purtroppo non sempre è possibile utilizzare questi comodi strumenti, oppure a causa di policy di gestione particolarmente rigide non è proprio possibile installare altro software.
In questi casi occorre sfruttare quello che fornisce il buon vecchio kernel, anzitutto abilitando le funzioni di debugging di scrittura blocchi sui dispositivi di IO portando a 1 il parametro block_dump:
echo 1 > /proc/sys/vm/block_dump
Una volta effettuata questa operazione basta interrogare il kernel ed estrarre i dati utili al nostro scopo:
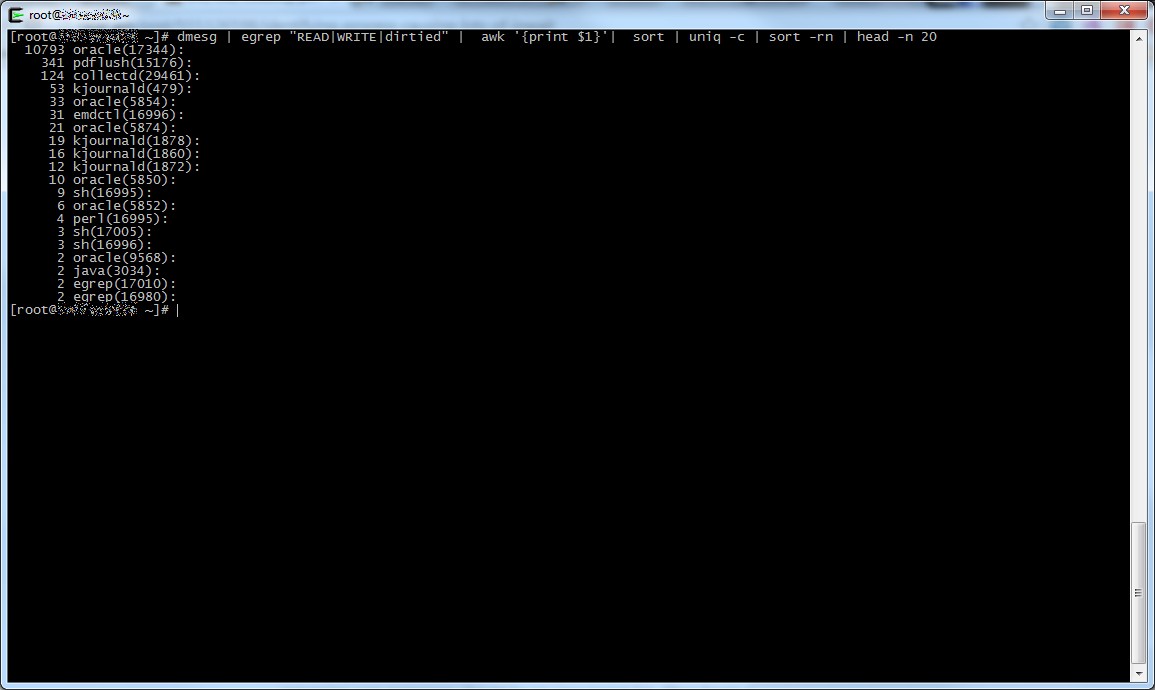
dmesg | egrep "READ|WRITE|dirtied" | awk '{print $1}'| sort | uniq -c | sort -rn | head -n 20
Il risultato è piuttosto chiaro e riporta i 20 processi (con tanto di pid tra parentesi) che generano il maggior carico di IO sul sistema da quando è stato attivato il debugging del kernel.
Al termine ricordatevi di riportare a zero il valore del parametro modificato precedentemente:
echo 0 > /proc/sys/vm/block_dump
A questo punto è possibile proseguire con l’indagine per scoprire per quale motivo il processo in questione sta impattando sul sottosistema di storage. Magari come me scoprirete qualche furbastro che alle 17:00 di venerdì ha pensato bene di lanciare un job particolarmente gravoso senza avvisare, e pensando che nessuno se ne accorgesse.
Ora vi lascio, devo preparare gli strumenti di tortura per l’interrogator… ehhhmm la verifica con l’utente lunedì prossimo ;)



