20/12/2013
Quick Bugzilla
 Uno degli strumenti che utilizzo frequentemente in ambito lavorativo e che personalmente apprezzo tantissimo è Bugzilla.
Uno degli strumenti che utilizzo frequentemente in ambito lavorativo e che personalmente apprezzo tantissimo è Bugzilla.
So bene che questo strumento è nato come tool di bug tracking, e per quanto abbia una struttura dichiaratamente general purpose non sarebbe l’ideale per la gestione di progetti o comunque come tool di trouble ticketing.
Dalla mia esperienza però purtroppo le aziende italiane sono scarsamente abituate ad una gestione strutturata dei problemi e tendono a inondare il povero consulente (o tecnico in generale) con una valanga di email, generando entropia “a gerle”; in scenari di questo tipo anche una semplice istanza Bugzilla può letteralmente cambiare la vita (in positivo), poi diciamocelo, come non amare un software con un logo così carino?
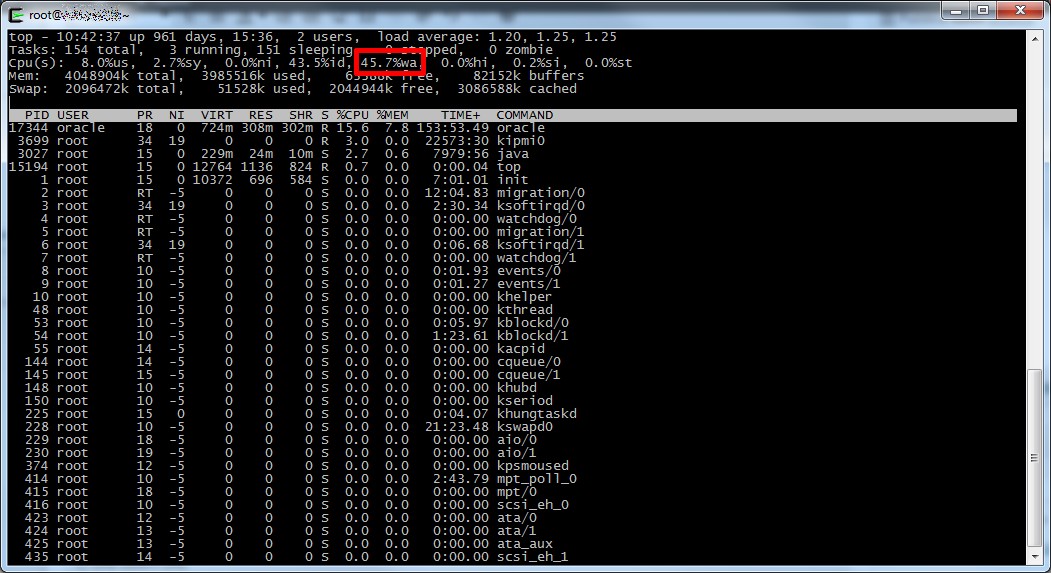
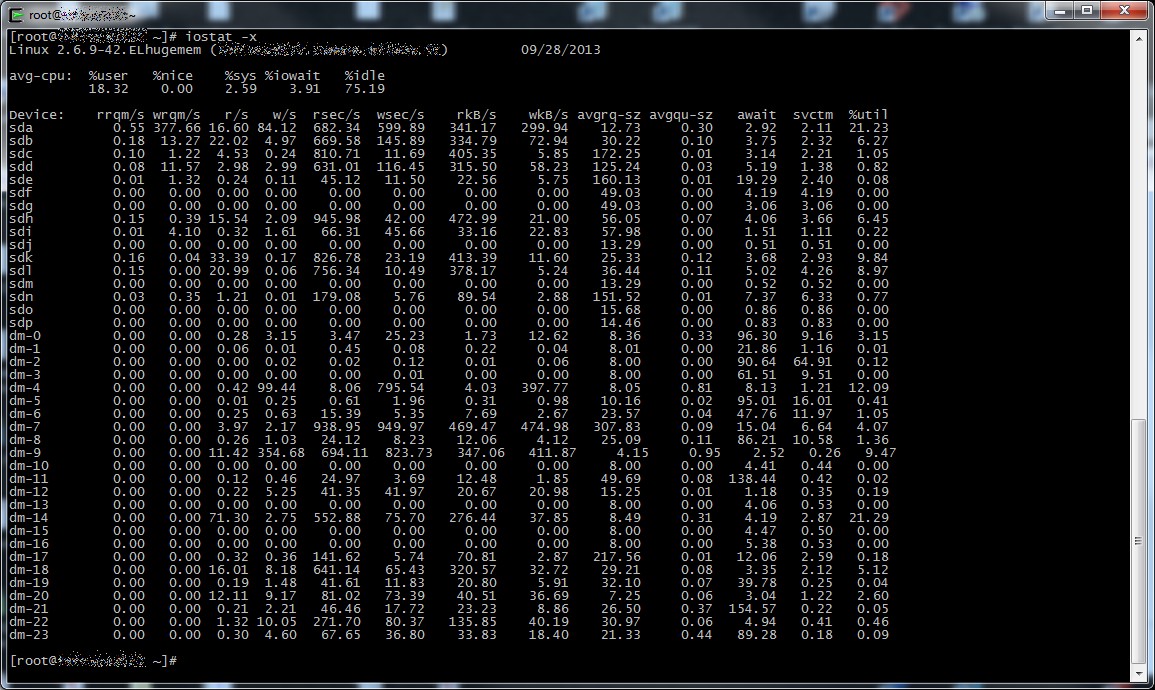
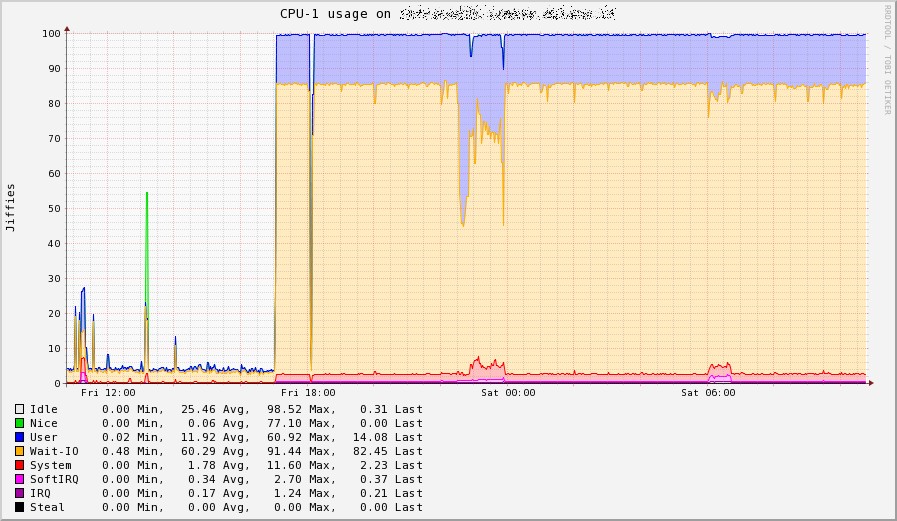
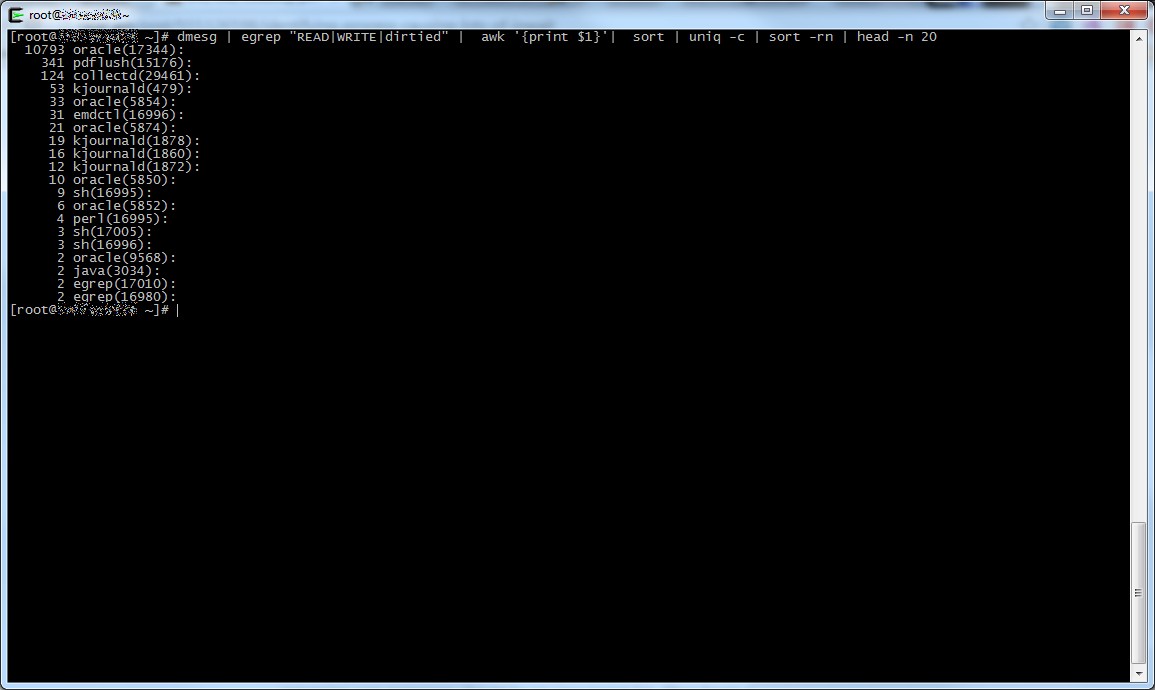
Come tutte le cose però anche Bugzilla non è esente da difetti, in particolare le vecchie versioni hanno un motore di ricerca imho molto macchinoso, e al crescere dei bug le performance risultano tutt’altro che brillanti.
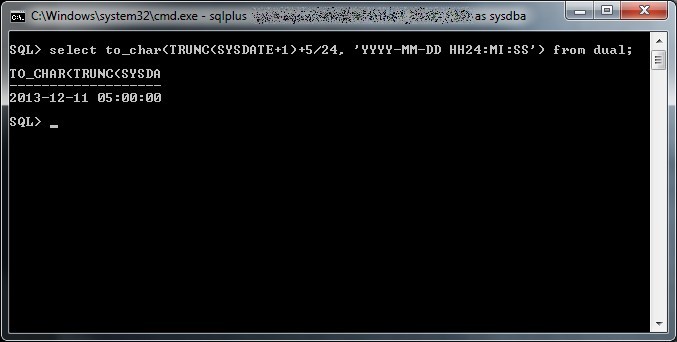
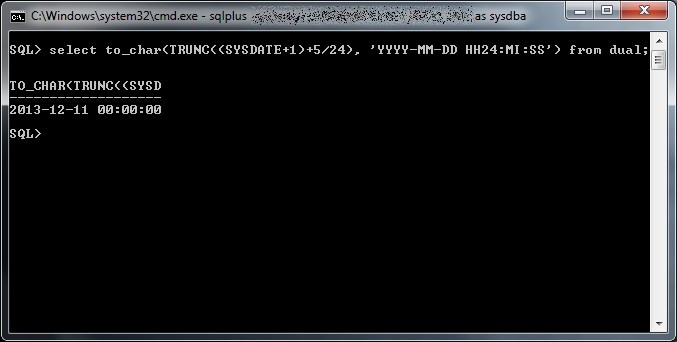
Guarda caso mi sono trovato proprio in questa situazione da un cliente, Bugzilla versione 2.22 su una altrettanto arcaica Debian Etch installata su un pc recuperato da uno sgabuzzino e oltre 8000 bug alle spalle, come potete immaginare fare query estese su questa istanza non è certo una passeggiata.
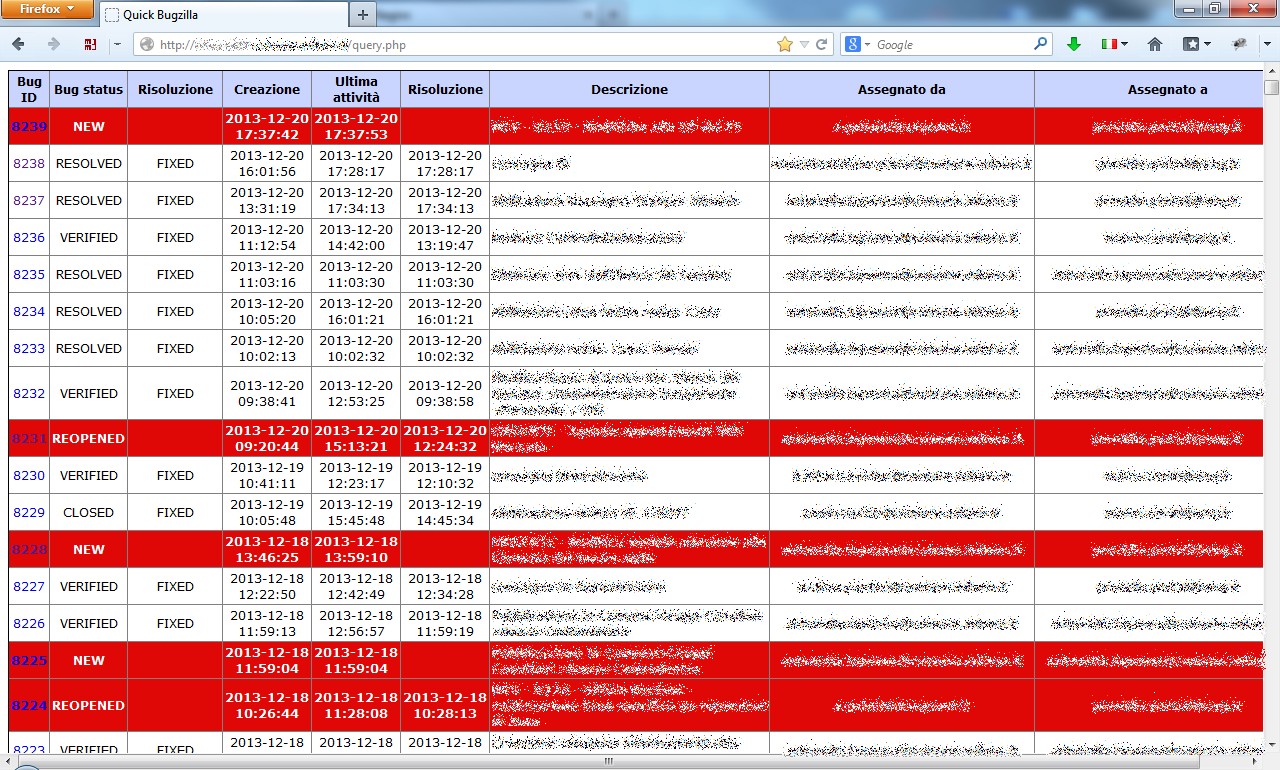
Preso dallo sconforto un giorno mi sono riservato un’oretta di tempo per buttar giù una semplice pagina php che andasse ad interrogare direttamente il database di Bugzilla per generare una tabella riassuntiva dei bug successivi ad una certa data, formattando i record con colori differenti in base allo stato del bug e che permettesse di aprire il dettaglio di ciascuno con un semplice link.
Il risultato è il seguente, ci tengo a precisare che:
- le mie skill di sviluppo php sono prossime allo zero assoluto
- la pagina viene utilizzata unicamente da rete trustata e il codice presente nella pagina è stato sviluppato in modo becero e in spregio a qualsiasi best practice
- la pagina effettua soltanto query di select, pertanto non è distruttiva, a prescindere da questo declino ogni responsabilità per qualsiasi utilizzo scorretto della stessa
- la pagina è stata sviluppata per interrogare il database MySQL di Bugzilla v. 2.22
Download: quick_bugzilla (2 KB)
MD5sum: a42afdbec6ea4cee123d04cb15fe6014
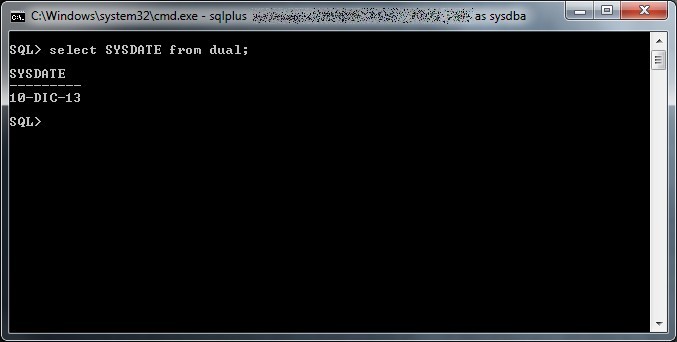
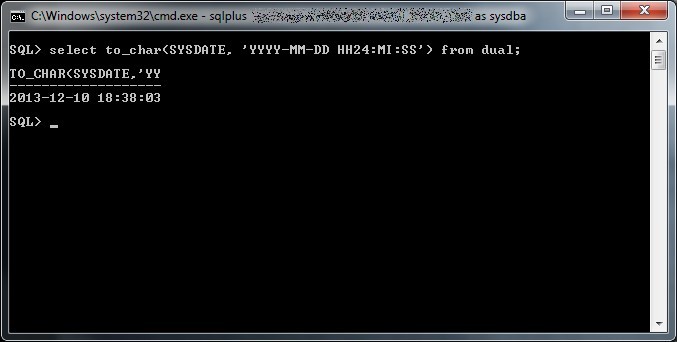
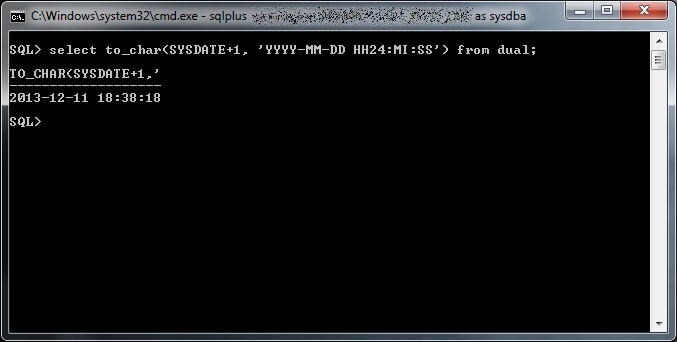
 Fin da quando ho cominciato a giocare con le prime distribuzioni GNU/Linux (si trattava del 1998 con una Redhat 5.0, seguita da una Debian potato un paio d’anni dopo) non ho potuto fare a meno di rimanere affascinato dall’universo IT che si contrapponeva al mondo commerciale, ciò nonostante non ho mai approfondito molto il concetto di free software, la storia della Free Software Foundation e l’opera di Richard Stallman.
Fin da quando ho cominciato a giocare con le prime distribuzioni GNU/Linux (si trattava del 1998 con una Redhat 5.0, seguita da una Debian potato un paio d’anni dopo) non ho potuto fare a meno di rimanere affascinato dall’universo IT che si contrapponeva al mondo commerciale, ciò nonostante non ho mai approfondito molto il concetto di free software, la storia della Free Software Foundation e l’opera di Richard Stallman.