Un software open source che utilizzo parecchio sui miei sistemi e su quelli dei miei clienti è Collectd, che ormai è diventato il mio standard in fatto di storicizzazione dei valori di carico e dell’andamento delle risorse sui miei server linux.
Si tratta di un ottimo software che non ha dipendenze clamorose (giusto rrdtool per conservare i dati in formato rrd), che rileva i dati direttamente dal sistema (/proc) e che soprattutto non si appoggia ad altro, in particolare al protocollo SNMP (come ad esempio il celebre Cacti); insieme all’ottimo Collectd Graph Panel permette di tenere tutto sott’occhio tramite una comoda (e bella) interfaccia web based in php.
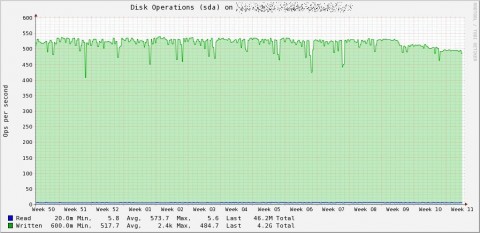
L’unico difetto di Collectd è che se utilizzato male tende a piegare lo storage più performante a causa dell’elevato numero di IOPS generati, il fenomeno è direttamente proporzionale al numero di database rrd utilizzati quindi si manifesta soprattutto se si utilizza il plugin network per centralizzare la raccolta dati su una singola macchina; il risultato è un server ridotto ad un 486 a causa dell’eccessiva sollecitazione del sottosistema di storage in termini di scritture.
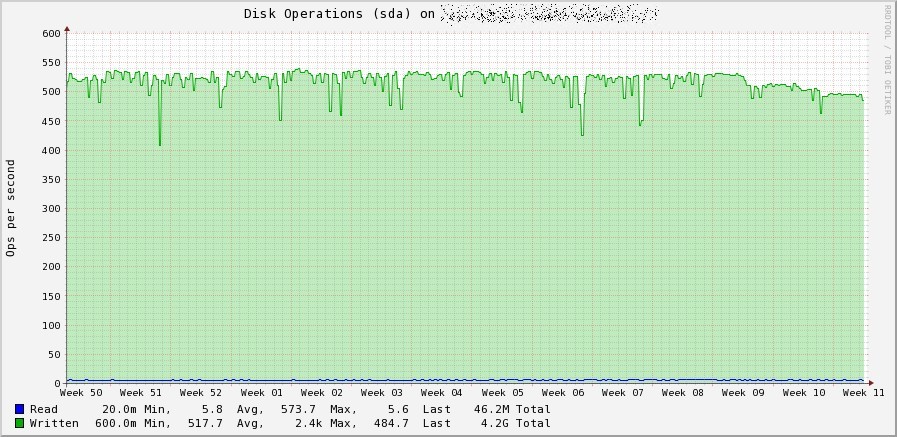
Qui potete vederne un esempio, si tratta di poche decine di server per un totale di circa 3800 file rrd collezionati mediante plugin network con le impostazioni di default, in pratica un chiaro caso di “I/O Hell”
Per risolvere il problema occorre da una parte un po’ di buon senso e dall’altra un paio di semplici accorgimenti nel file di configurazione (/etc/collectd.conf).
1) Raccogliete i dati che servono, evitate il resto.
Sembrerà una banalità ma spesso di default sono attivi un sacco di plugin che in realtà su molte macchine non servono, se ad esempio state monitorando un server su cui vengono fatti accessi locali solo a scopo amministrativo, e questi vengono loggati altrove, che senso ha attivare il plugin users e generare degli rrd inutili?
2) Fate attenzione ai device del plugin disk.
I server connessi ad una san spesso si ritrovano con un gran numero di lun e di conseguenza di device di storage, se per giunta utilizzano LVM si generano una serie di altri device rilevati dal plugin “disk” (/dev/dm-*) che rappresentano i device map dei logical volumes, valutate se vi serve davvero monitorarli, ed eventualmente escludeteli limitandovi ai device fisici (es /dev/sd*)
3) Utilizzate il plugin rrdtool solo dove serve.
Se raccogliete i dati su un server centralizzato tramite plugin network è inutile (e ridondante) conservare gli stessi dati anche in locale, genererete il doppio degli IOPS (sulle interfacce di rete e sui device di storage locali) senza alcun reale beneficio (se volete un backup fatelo sul server che raccoglie tutti gli rrd…).
4) Utilizzate le opzioni CacheTimeout e CacheFlush del plugin rrdtool.
Queste sono la vera manna nel caso di I/O Hell, abilitando questi due parametri Collectd non scriverà ogni modifica ai file rrd istantaneamente ma la terrà in RAM per un certo numero di secondi (definito dal parametro CacheTimeout), al termine dei quali effettuerà un’unica scrittura. Il parametro CacheFlush forza la pulizia della cache dopo un certo numero di secondi, giusto per fare “pulizia” nel caso qualche server abbia smesso di rispondere oppure qualche rilevazione sia rimasta in sospeso per qualsiasi motivo.
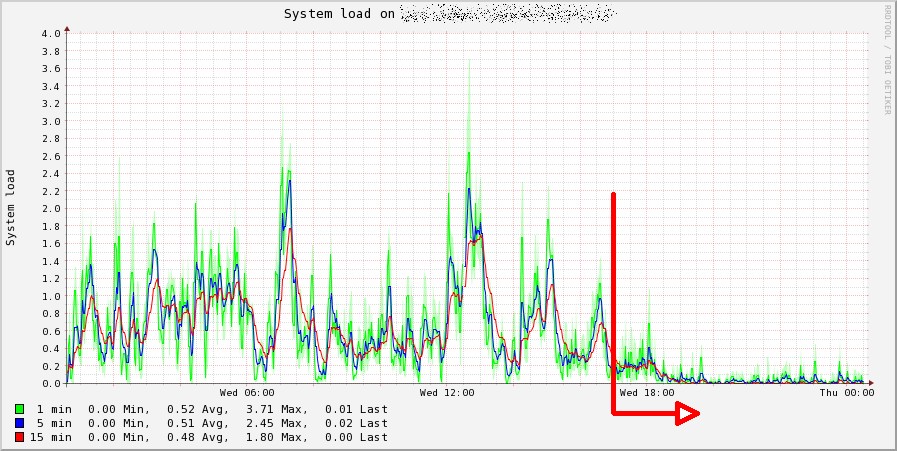
Potete osservare l’impatto di queste modifiche nel grafico che segue
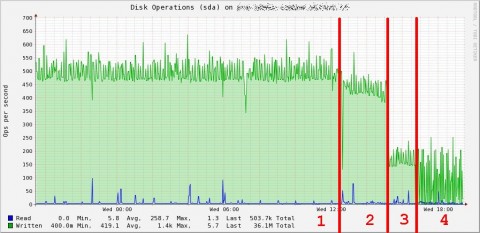
- I/O Hell (1)
- Rimozione dei plugin inutili e dei device poco significativi (2)
- Attivazione CacheTimeout con frequenza pari a 120″ (3)
- Attivazione CacheTimeout con frequenza pari a 300″ (4)
Come potete osservare il numero di IOPS si è DRASTICAMENTE ridotto, e soprattutto non si verifica più l’affollamento di scritture presente prima della modifica.
Come risultato il server finalmente è tornato ad avere tempi di risposta fulminei (in precedenza aprire la homepage di Collectd Graph Panel richiedeva una trentina di secondi buoni, generare una decina di grafici poteva richiedere anche un minuto o più) e il carico di sistema ne ha beneficiato.
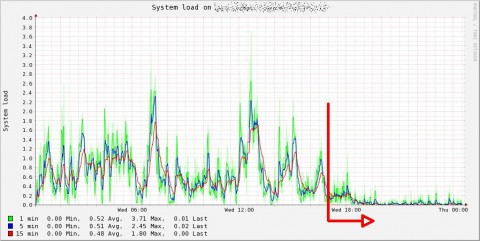
L’unica conseguenza negativa di questa operazione è il fatto che i grafici non vengono più aggiornati in real time ma soltanto quando il plugin rrdtool salva i dati nei file rrd, un disagio tutto sommato accettabile considerando i benefici, senza contare che il ritardo è passibile di tuning in base al livello di carico e al numero di rrd file da gestire.