14/07/2014
OVH VPS Classic
Eccomi qui a distanza di un anno esatto ad affrontare l’ennesima migrazione del blog (che ormai somiglia sempre più a un ambiente di test per provider).
Dopo aver aver provato l’ottimo servizio di hosting di Siteground ho mio malgrado deciso di cambiare aria, non certo per la qualità del servizio (sempre ottima), ma per una pura questione di costi; al termine dell’anno promozionale l’hosting condiviso base di Siteground lievita a quasi 100 $ l’anno, decisamente troppo per il mio target.
A questo punto il dubbio amletico: hosting o vps?
OVH ha deciso di togliermi ogni dubbio in merito con una offerta che francamente ha del miracoloso, ovvero VPS Classic:
- 1 CPU Opteron 4284 3GHz
- 1 GB di ram
- 10 GB di storage
- banda e traffico a carrettate
…il tutto alla modica cifra di 2,43 € al mese iva inclusa.
Il servizio di primo acchito sembra essere ottimo, ordine e pagamenti semplici e immediati, tempo 5 minuti dal pagamento e sarete già connessi in ssh al vps.
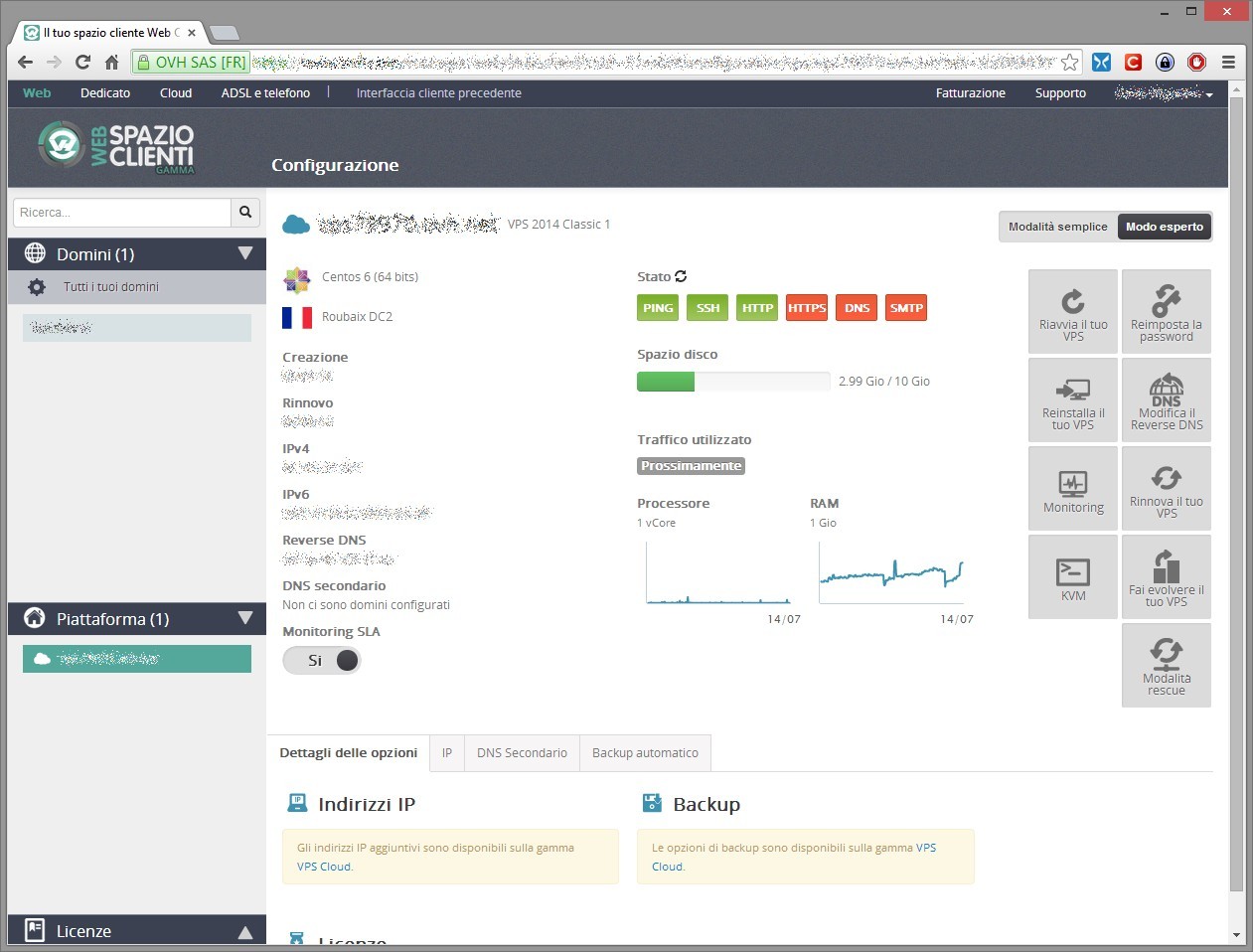
L’interfaccia di amministrazione è pulita e molto funzionale, la schermata principale mostra le risorse della macchina, gli ip, lo stato dei servizi in ascolto (http, https, ssh, dns, smtp e raggiungibilità via ping) e poco altro.
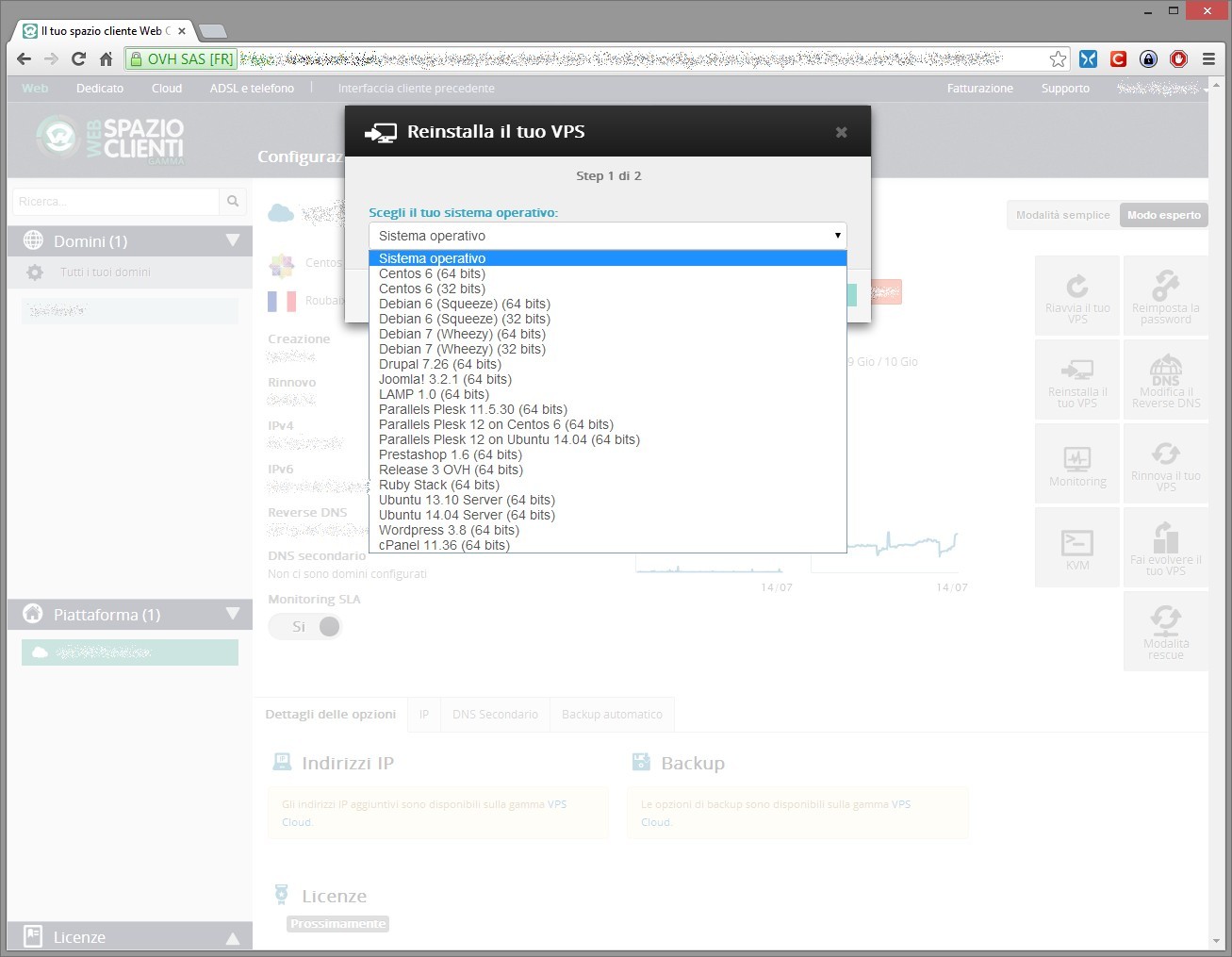
Accedendo ai menù avanzati è possibile verificare l’andamento delle principali risorse in modo più dettagliato, riavviare, modificare la password di root (il che causa un riavvio del vps), modificare il contratto o rinnovarlo, e reinstallare il vps scegliendo tra diverse distribuzioni (Debian 6 e 7, CentOS 6, Ubuntu 13.10 e 14.04) o setup che comprendono alcuni dei cms più diffusi o pannelli di amministrazione.
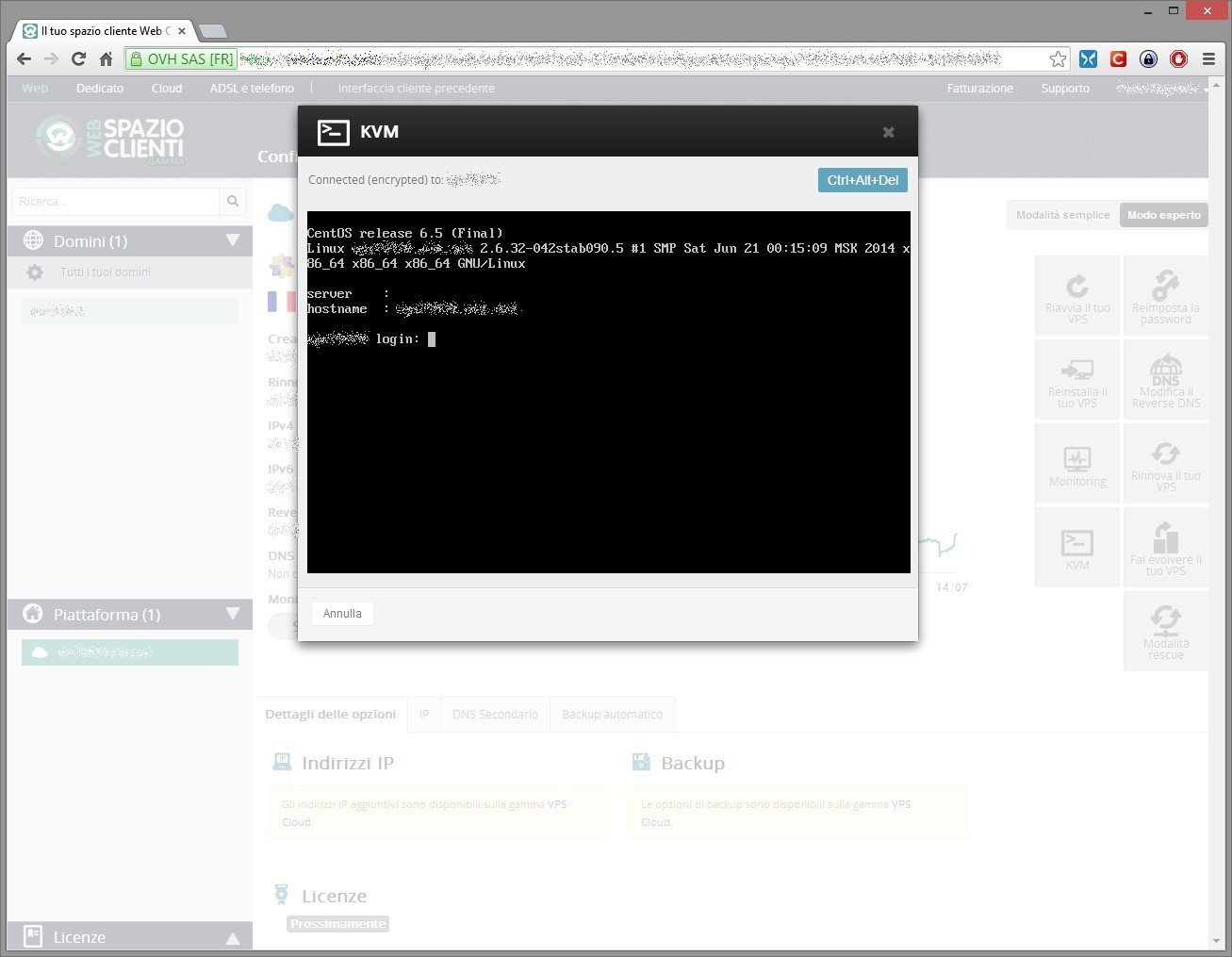
Ovviamente non manca un comodo KVM che permette di accedere alla console del vps, giusto nel caso abbiate pasticciato un po’ con la rete e iptables.
Le performance sono… eh no, queste le vedremo prossimamente, diciamo che per ora sono più che soddisfatto :D