18/10/2014
WebSEAL headers encoding
Lavorando con WebSEAL su un virtualhost junction mi è recentemente capitato di avere qualche disguido, nello specifico si è trattato di un virtualhost junction ad accesso riservato dove l’applicazione di backend in single sign-on catturava lo UID dell’utente (passato tramite variabile IV_USER) e lo utilizzava per attività di vario genere.
Abbiamo osservato una anomalia quando l’utente effettuava la login inserendo degli spazi in coda allo username (es “utente ” anzichè “utente”), mentre WebSEAL lo autenticava correttamente l’applicazione di backend generava una serie di eccezioni che si manifestavano con un loop continuo di richieste http.
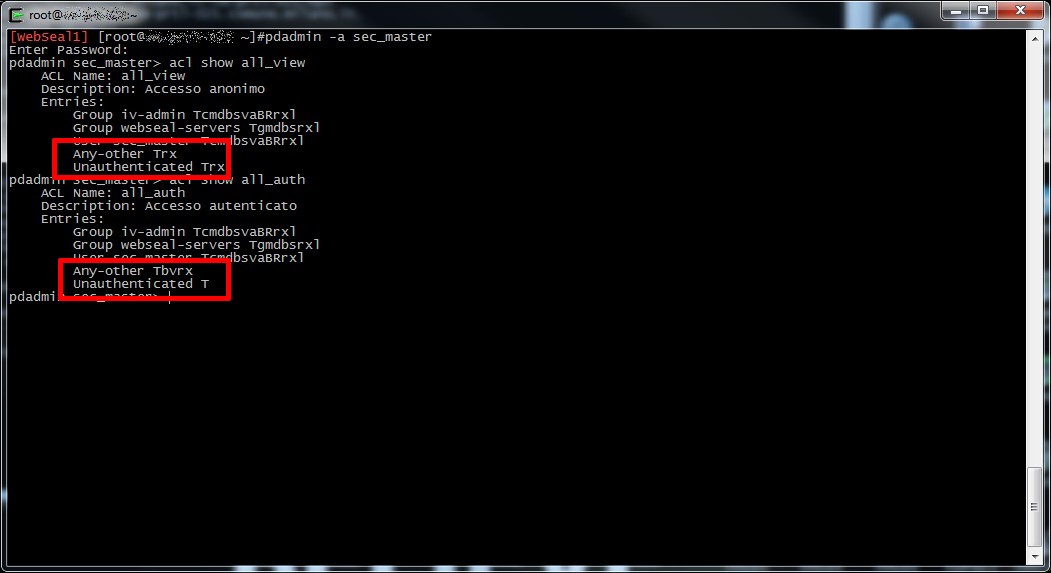
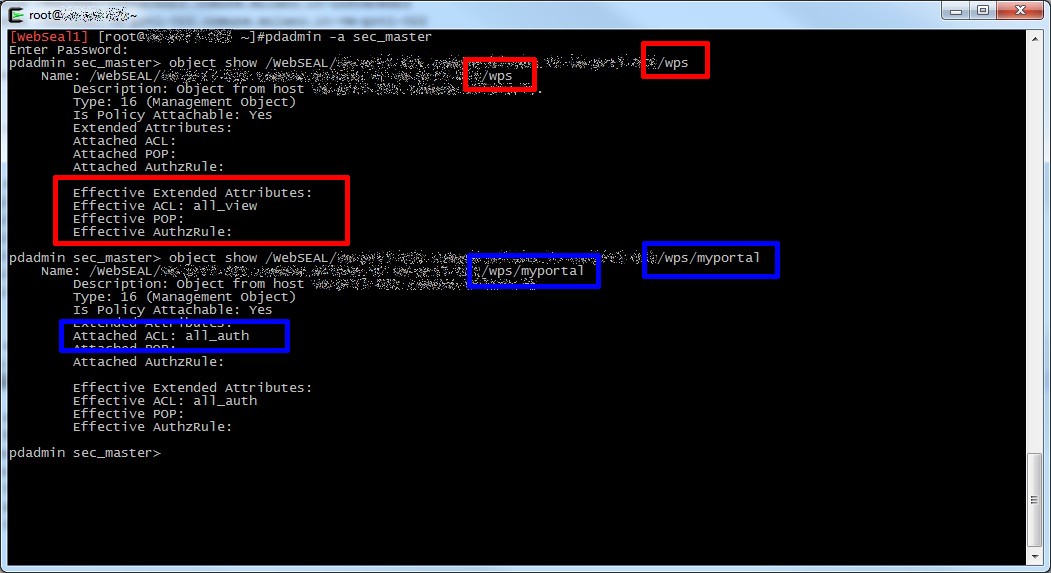
Verificando l’anomalia ho provato a riprodurla su un ambiente di sviluppo, ricreando il virtualhost junction nello stesso modo e associando all’oggetto l’acl per forzare la login (all_auth).

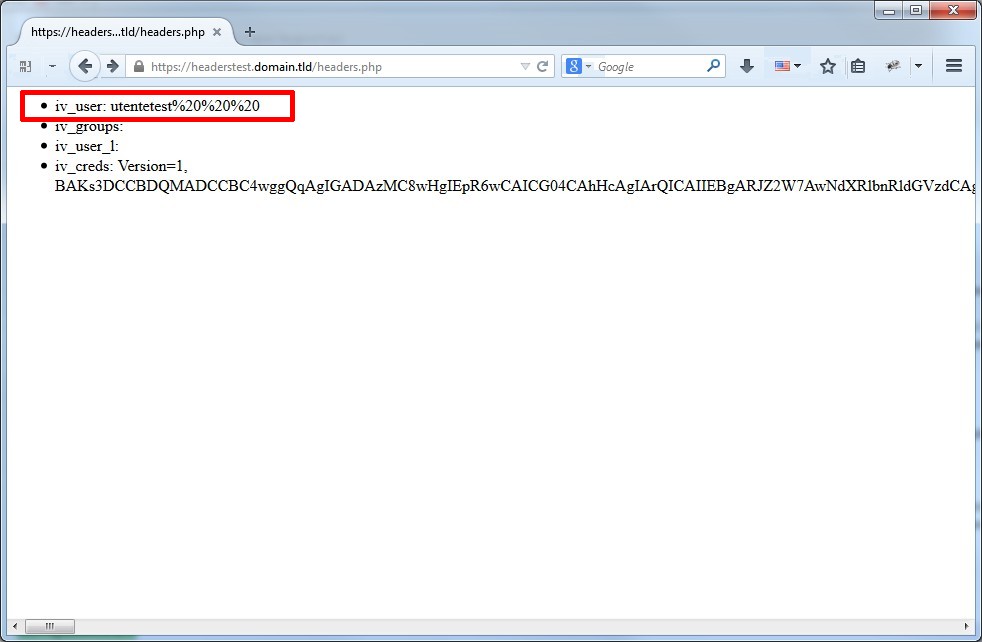
In questo caso ho utilizzato come risorsa di backend un banalissimo webserver php dove ho piazzata una semplicissima pagina (headers.php) che estraesse le variabili passate da WebSEAL (-c all), in particolare la variabile IV_USER:
<?php $user = $_SERVER['HTTP_IV_USER']; $groups = $_SERVER['HTTP_IV_GROUPS']; $userl = $_SERVER['HTTP_IV_USERL']; $creds = $_SERVER['HTTP_IV_CREDS']; ?> <ul> <li>iv_user: <?php echo $user ?></li> <li>iv_groups: <?php echo $groups ?></li> <li>iv_user_l: <?php echo $userl ?></li> <li>iv_creds: <?php echo $creds ?></li> </ul>
Il risultato di una login con spazi in coda allo username è stato il seguente.
GOTCHA!
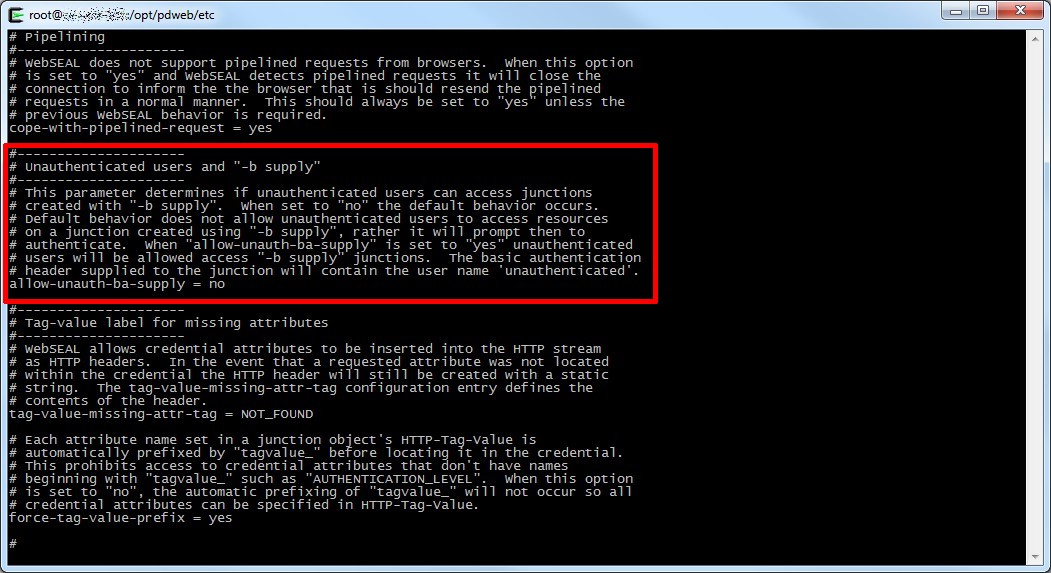
Verificando sull’infocenter IBM ho trovato una technote che descrive proprio il problema in questione (anche se riferito ad un problema sul componente di integrazione SSO ETAI, che nel caso specifico non stavo utilizzando).
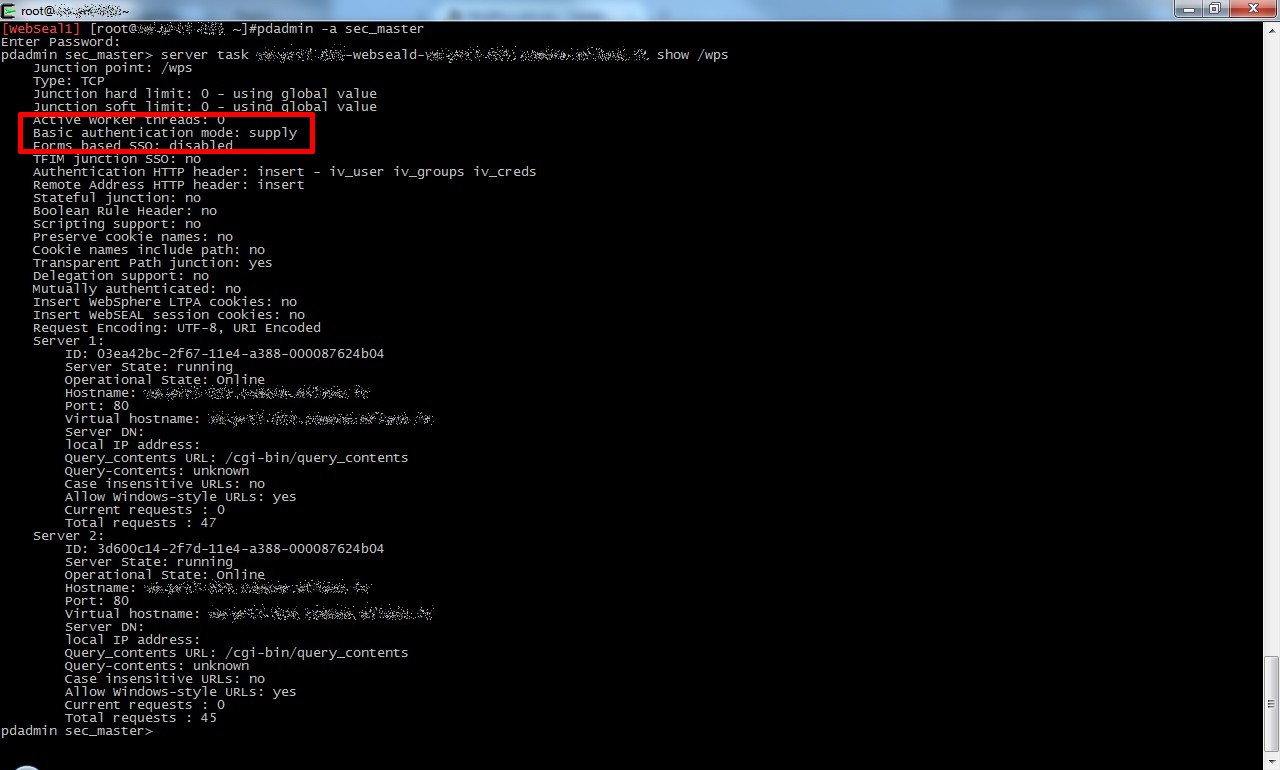
La soluzione consiste nel creare il virtualhost junction configurando gli headers con encoding “UTF8 Binary” anzichè “UTF8 URI Encoded” (parametro -e utf8_bin)

Una volta effettuata questa piccola modifica il risultato è stato il seguente e il problema si è risolto.