08/08/2013
Personalizzare il prompt bash
Della serie “tips & tricks per tutti” parliamo di un’altro semplice trucchetto a costo zero utilissimo per evitare di fare tutte quelle cose che in gergo tecnico e strettamente sistemistico si definiscono MINCHIATE.
Lavorando prevalentemente su console testuali (es terminali virtuali di server GNU/Linux, magari via ssh) capita di aver aperto contemporaneamente parecchi terminali verso diverse macchine.
Lavorare in questo modo presenta innumerevoli vantaggi, è un modo veloce, snello e immediato per poter fare qualsiasi cosa in brevissimo tempo.
Ad un utente comune potrà sembrare arcaico ma vi assicuro che se dovessi riconvertirmi a sistemista Windows impazzirei, o quantomeno sarei molto meno produttivo dovendo tornare ad una interfaccia prevalentemente grafica, non a caso la prima cosa che faccio quando prendo in mano una macchina Windows è installare cygwin e OpenSSH.
A questo dettaglio tecnico aggiungete la classica disorganizzazione e arroganza del cliente tipico italiano (già, proprio quello che pretende le cose fatte “per ieri”), le offerte folli dei commerciali (avete presente l’espressione “vendere la pelle dell’orso prima di averlo ucciso”?), il caos imperante in qualsiasi CED, shakerate bene e otterrete un mix letale di pessime condizioni operative, in questa situazione capite bene che è molto facile confondere un terminale per un altro :(
Provate a immaginare il brivido che vi corre lungo la schiena appena vi siete accordi di aver droppato un database su un server di produzione anzichè quello di test…
Per evitare tutto questo, o per lo meno per renderlo meno probabile basta un semplicissimo accorgimento, personalizzare il prompt del terminale.
E’ sufficiente ad esempio aggiungere una label prima del prompt, magari di un colore differente a seconda della criticità del sistema come in questo esempio
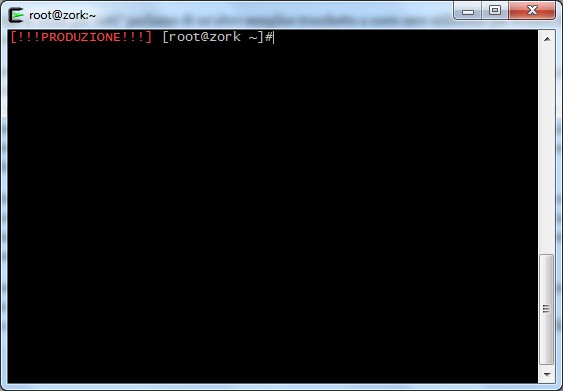
Per fare questo è sufficiente modificare gli script di inizializzazione della bash per il proprio utente oppure per tutto il sistema, esportando opportunamente la variabile PS1 (Default interaction prompt).
Ad esempio per ottenere il prompt visibile nello screenshot su RedHat Enterprise o CentOS è sufficiente esportare la variabile con questo comando:
export PS1='\[\e[1;31m\][!!! PRODUZIONE !!!]\[\e[m\] [\u@\h \W]\$'
Per rendere la modifica attiva ad ogni login è sufficiente modificare gli script di init della bash (es .bashrc o .bash_profile nella propria home directory, oppure /etc/profile o /etc/bashrc, oppure aggiungere uno script in /etc/profile.d/) in modo che la variabile venga esportata come meglio preferite ad ogni login.


 Oggi si sente un gran parlare di servizi di streaming audio per portarsi appresso tutta la propria musica ovunque ci si trovi, servizi tipo Spotify o altre vaccate simili promettono mari e monti, salvo poi ritrovarsi inondati da una tale quantità di brani da non saper più quale scegliere…
Oggi si sente un gran parlare di servizi di streaming audio per portarsi appresso tutta la propria musica ovunque ci si trovi, servizi tipo Spotify o altre vaccate simili promettono mari e monti, salvo poi ritrovarsi inondati da una tale quantità di brani da non saper più quale scegliere…