Proprio durante queste feste mi sono ritrovato a fronteggiare un problema abbastanza rognoso su un cluster WebSphere Portal 6.0, come da tradizione i problemi più bloccanti sono quasi sempre originati da cause che più banali non si può…
Lo scenario in cui si è presentato il problema è il seguente:
- cluster WPS 6.0 composto da 4 nodi distribuiti su due server fisici, uno dei quali ospitante deployment manager
- OS RedHat Enterprise Linux ES 4 x86
- shutdown dell’intero cluster per attività di manutenzione sul dbms Oracle 10g utilizzato dal cluster
- al riavvio del cluster solo uno dei 4 nodi WPS non effettua lo startup bloccandosi immediatamente dopo il comando di avvio (sia tramite interfaccia dmgr che tramite script startServer.sh)
E’ parso chiaro fin da subito che la causa non potesse essere legata al dbms o altri servizi di supporto (es ldap) in quanto gli altri nodi che utilizzano le medesime risorse risultavano funzionare perfettamente, a prescindere da ciò il problema si presentava molto prima che il servizio potesse anche solo inizializzare le connessioni a ldap o database; escluse queste componenti non è restato da fare altro che concentrarsi su JVM e sistema operativo.
Analizzando la directory che contiene i log del nodo ho notato che:
- la gran parte dei log presentava timestamp allineato e corrispondente allo shutdown del nodo (effettuato tramite deployment manager, nessun SIGKILL di processo o altre porcate del genere).
- L’unico log modificato al momento dello startup è risultato essere lo startServer.log, aprendo il quale non risultano esserci indicazioni particolarmente utili.
- Nei log di stdout (SystemOut.log) e stderr (SystemErr.log) della JVM non risultano record significativi tranne poche eccezioni relative a transazioni non completate verso i datasource JDBC (risolvibili mediante avvio in modalità recover, oppure eliminazione dei trasactlog e partnerlog WPS).
Sniffando il traffico tra nodo WPS e listener Oracle durante l’avvio del nodo problemativo non risultano alcuna comunicazione, pertanto si escludono problemi legati ai datasource o alle transazioni con il repository dbms.
- Non sussistono problemi legati ai permessi di lettura/scrittura sui filesystem dove risiedono i file del servizio, il file di pid non è presente e non ci sono processi in ascolto su porte utilizzate dal nodo WPS.
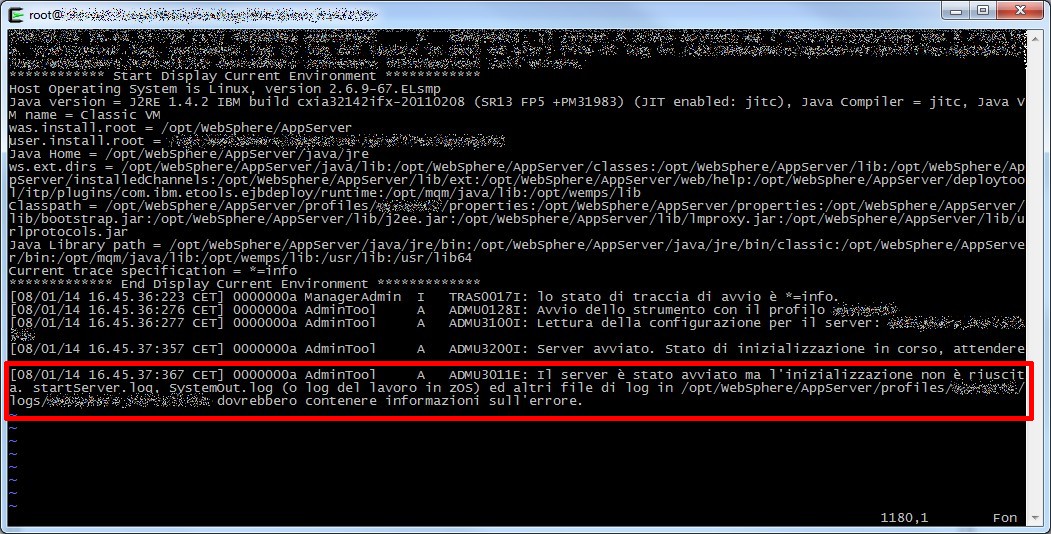
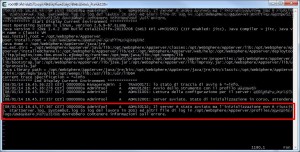
A questo punto stavo cominciato a brancolare nel buio, verificando nella directory WAS_HOME ho rilevato un file javacore.txt con timestamp corrispondente allo shutdown del nodo, spulciando tra le prime righe di questo file di trace ho notato una indicazione chiave.
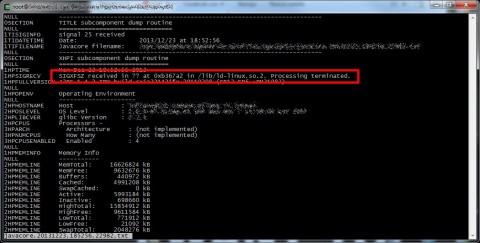
Da Wikipedia: “The SIGXFSZ signal is sent to a process when it grows a file larger than the maximum allowed size”
A questo punto mi sono messo alla ricerca di file di dimensioni considerevoli nelle principali directory dove il servizio (o i processi del servizio) vanno a scrivere, principalmente logs.
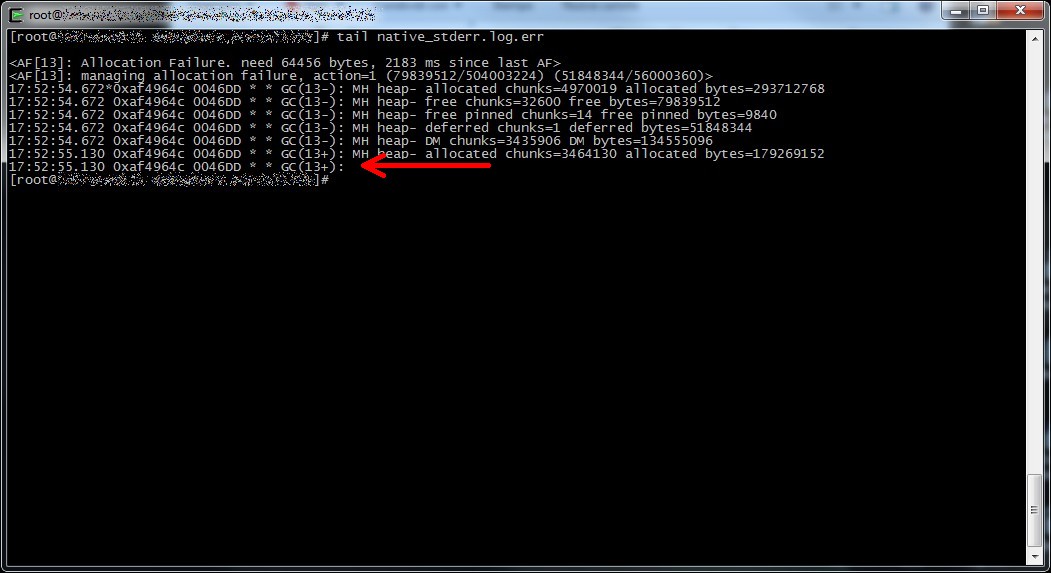
Proprio nella directory dei log del nodo era presente il log di errore del Garbage Collector JVM (native_stderr.log) di dimensione “abbastanza” sospetta: 2GB precisi precisi.
Aprendonolo risulta che l’ultimo record in coda risulta stranamente troncato.
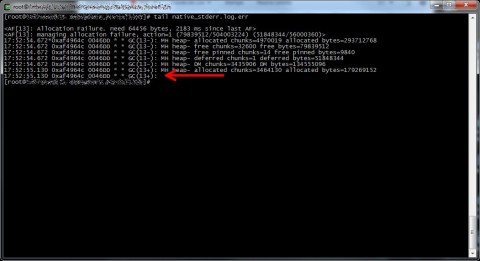
Dopo aver svuotato il log il nodo è magicamente partito e non ha mostrato alcun segno di anomalia!
VITTORIA! :)