

28/01/2013
Monitoraggio logs con Nagios
Monitorare i log è un’attività spesso tediosa ma fondamentale per essere certi del corretto funzionamento di un servizio, un modo per rendere tutto più semplice e automatico è sfruttare il buon vecchio Nagios in combutta con l’ottimo plugin check_logfiles.
Il vantaggio di questo plugin rispetto a soluzioni più “caserecce” (es script bash che ‘greppa’ il file di log e genera un output differente in base alla presenza o meno del pattern ricercato) consiste prima di tutto nel fatto di concentrare in un unico service il monitoraggio di differenti log, in secondo luogo check_logfiles non riprocessa i pattern già rilevati e segnalati, evitando quindi di ricevere molteplici segnalazioni relative allo stesso problema.
L’installazione e configurazione è a dir poco banale:
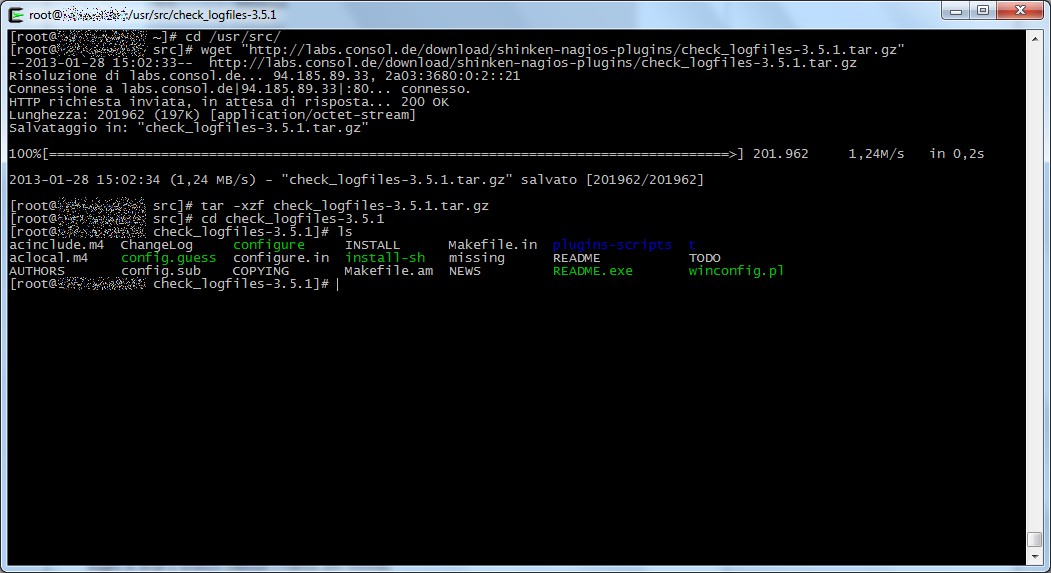
- scaricate l’archivio tar.gz dal sito ufficiale, decomprimetelo (nell’esempio in /usr/src) ed entrate nella directory creata
- lanciate il consueto ./configure, i parametri di default andranno più che bene per la maggior parte dei casi, nel caso doveste personalizzarli lanciate il comando seguito da –help per visualizzare tutti i possibili parametri.
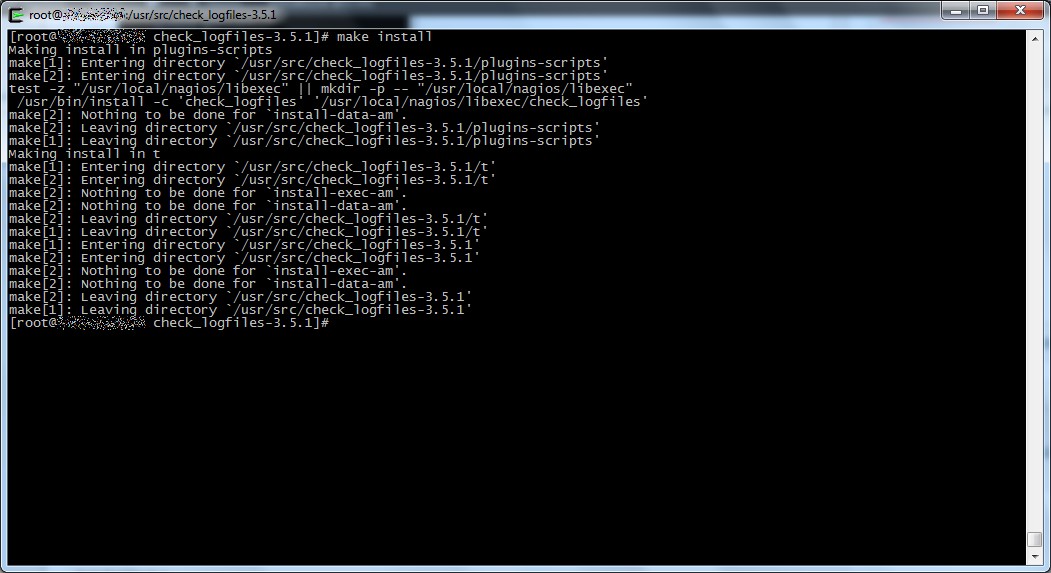
- compilate i sorgenti lanciando il comando make
- installate i file lanciando il comando make install
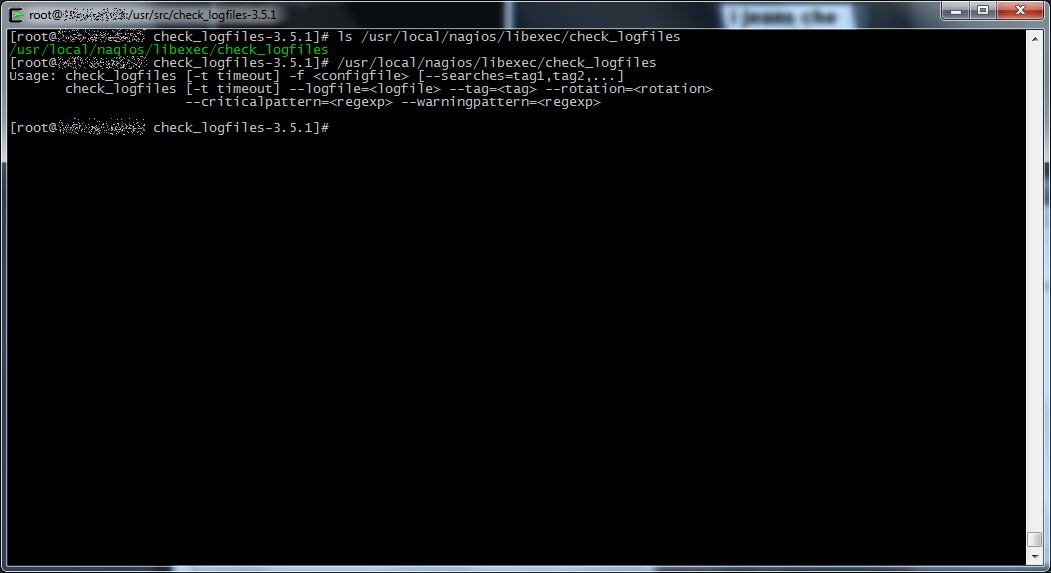
- al termine dell’installazione il binario del plugin sarà disponibile in /usr/local/nagios/libexec/check_logfiles (ovviamente a patto di non aver modificato il parametro –previx, in caso contrario verificate nel percorso che avete definito come valore di quel parametro).


A questo punto l’installazione del plugin è completata, non resta che configurare il service direttamente su nagios.
Una soluzione più razionale e comoda può essere quella di definire un solo service e utilizzare nrpe per effettuare la verifica remota, definendo lo stesso comando su tutti i server da monitorare e limitare la personalizzazione al solo file di configurazione di check_logfiles.
Create il file di configurazione di check_logfiles (es /usr/local/nagios/libexec/logfiles.cfg) con un qualsiasi editor di testo e inserite la sintassi necessaria a verificare il vostro file di log, i parametri da modificare sono:
- ‘tag’ (inserite una descrizione del log che state controllando)
- ‘logfile’ (devo spiegare?)
- ‘warningpattern’ (elenco di pattern da cercare nel log che scatena un alert warning in Nagios)
- ‘criticalpattern’ (elenco di pattern da cercare nel log che scatena un alert critical in Nagios)
Quello che segue è un esempio di file di configurazione per monitorare il file catalina.out di una istanza Tomcat posta in /opt/jakarta-tomcat-5.0.28, ciascun avvio di Tomcat (org.apache.catalina.startup.Catalina start) scatena un alert warning, mentre episodi di Out of memory ed esaurimento del pool di connessione ai datasource scatenano un alert di tipo critico.
@searches = (
{
tag => 'tomcat_catalina.out',
logfile => '/opt/jakarta-tomcat-5.0.28/logs/catalina.out',
warningpatterns => [
'org.apache.catalina.startup.Catalina start',
],
criticalpatterns => [
'OutOfMemoryError',
'pool exhausted',
],
});
Una volta configurato il file logfiles.cfg non resta che editare il file di configurazione di nrpe (/etc/nagios/nrpe.conf o equivalente) aggiungendo la riga che segue (verificate sempre il path in base alle vostre esigenze):
command[check_logfiles]=/usr/local/nagios/libexec/check_logfiles --config /usr/local/nagios/libexec/logfiles.cfg
Riavviate il servizio per rendere effettivo il nuovo command check_logfiles (/etc/init.d/nrpe stop && /etc/init.d/nrpe start).
A questo punto la configurazione del plugin e di nrpe è terminata, non vi resta che aggiungere il service sul server Nagios e associarlo al server che volete monitorare, a titolo di esempio il servizio potrebbe essere definito come segue:
define service{
use generic-service
host_name hostdamonitorare.domain.tld
service_description Controllo logs
check_command check_nrpe!check_logfiles
max_check_attempts 1
}
Naturalmente la configurazione del service e degli host a cui applicare questo controllo varia a seconda della vostra configurazione di Nagios e della modalità con cui preferite associare services a hosts, l’unico parametro differente rispetto alla configurazione standard dei services è il numero di verifiche necessarie per far scattare l’evento warning o critico che deve essere impostato a 1 (max_check_attempts).
Dato che ogni controllo di check_logfiles verifica soltanto i record del file di log modificati dall’ultimo controllo è essenziale che i warning (e relative notifiche email o sms) partano alla prima rilevazione dei pattern definiti nel file di configurazione.
Per questo motivo è essenziale che questo service non utilizzi il consueto meccanismo di alert softt e hard di Nagios con la sequenza standard di 4 rilevazioni per scatenare la notifica.
Ecco fatto, ora non avete più scuse per ignorare un OutOfMemory ;)




